How to add search to CloudCannon CMS with OpenSearch
Peter Speak12 min read
1. Intro
Setting up effective search functionality for applications that rely on content management systems (CMS) is a crucial yet challenging task. In today’s digital landscape, the ability to seamlessly integrate robust search capabilities into applications is essential for enhancing user experience and ensuring quick access to relevant content.
CloudCannon is quickly becoming a name to remember in the world of content management systems. Offering versatile CMS capabilities, it provides significant flexibility in designing content environments. As a platform, CloudCannon encourages content creation and ensures data stays structured. In this post, I detail my experience integrating content from CloudCannon into an AWS OpenSearch Domain, enabling a robust content system ready for any use.
If you are new to CloudCannon, I would highly recommend starting with this tutorial written by my colleague Ana. It provides an excellent foundation, which I build upon in this article, demonstrating the powerful synergy between CloudCannon and AWS OpenSearch. I will reference Ana’s work, expanding on her example by adding search function to her recipe site.
1.1. Definition of terms
Before diving deeper, let’s define key terms that will be frequently used throughout this article:
OpenSearch Domain: OpenSearch is a search service provided by AWS. The OpenSearch Domain is the combination of the settings, storage and instance types used for search. More Info
Search index: A search index is where the data is stored and provides a way to organize your data within the domain. Domains can contain any number of indexes, helping make your data more consumable.
Eleventy: Also known as 11ty, a static site generator, used to keep the content and design of a site separated. However, it is flexible in that it can take many different data inputs and write them out to consumable JSON.
Amazon CDK (Cloud Development Kit): The AWS Cloud Development Kit (CDK) is an open-source software development framework for defining AWS cloud infrastructure with code. It allows developers to define their cloud resources using familiar programming languages, providing an efficient way to create and manage AWS resources such as OpenSearch domains, Lambda functions, and more.
Amazon SQS (Simple Queue Service): Amazon SQS is a fully managed message queuing service for microservices, distributed systems, and serverless applications.
2. The process
2.1. Basic CloudCannon publishing workflow
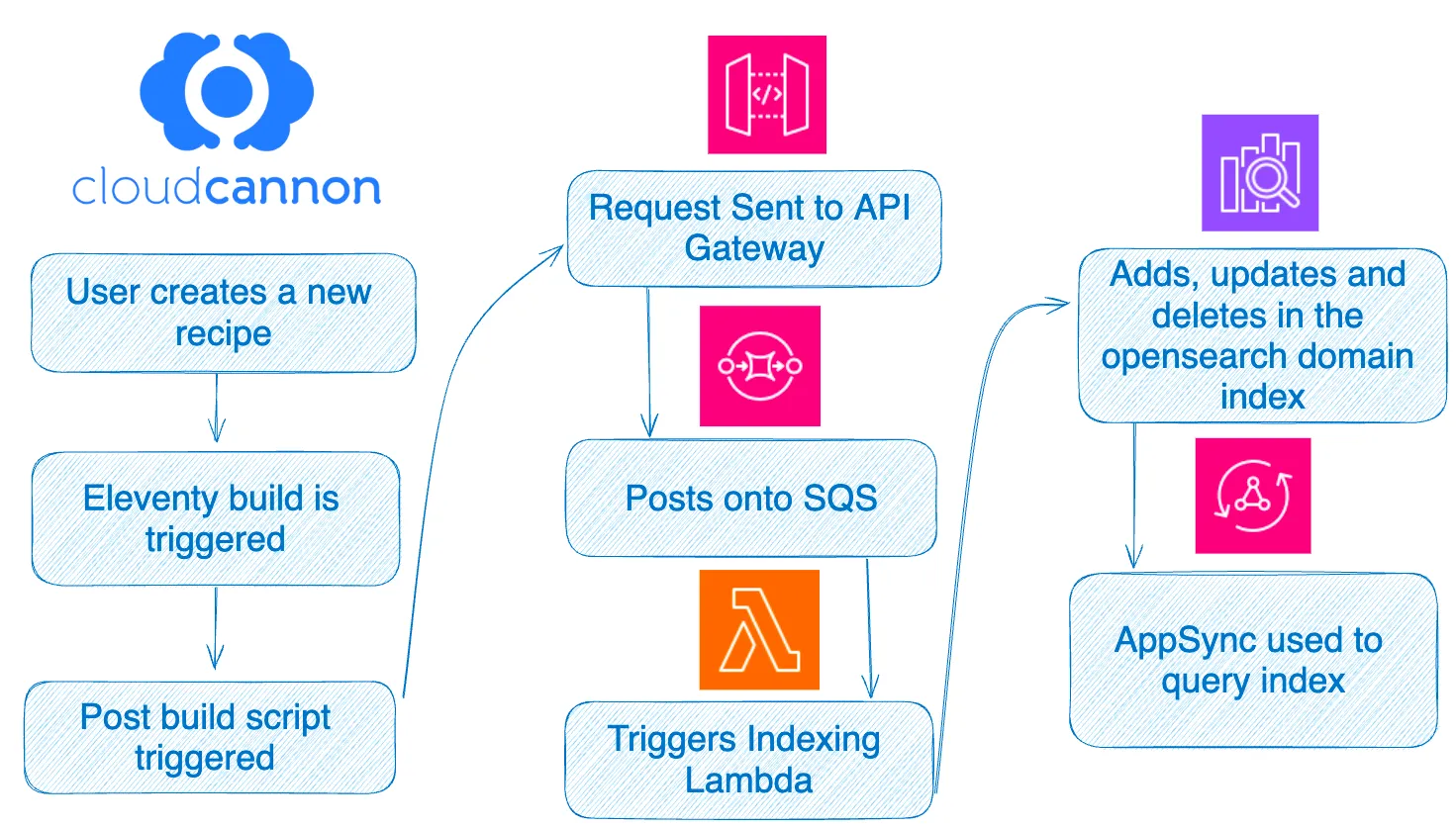
To start, we should have a solid understanding of how a CloudCannon publish workflow executes. When a user in CloudCannon creates new content, for example, a recipe for barbacoa tacos, a build is triggered. This build is completely configurable and in my case I chose to use the static site generator, Eleventy.
It is important to capture why Eleventy is used in this specific CloudCannon setup. It is used to keep the CMS headless. In this context, Eleventy’s role is crucial. It is not focused on generating web pages; it is focused transforming CMS content into structured JSON files. This approach differs significantly from Ana’s, where the CMS included a presentation layer. In our scenario, Eleventy bridges the gap between content management and application consumption, making it easier to pass the data into OpenSearch.
2.2. Adding search to the workflow
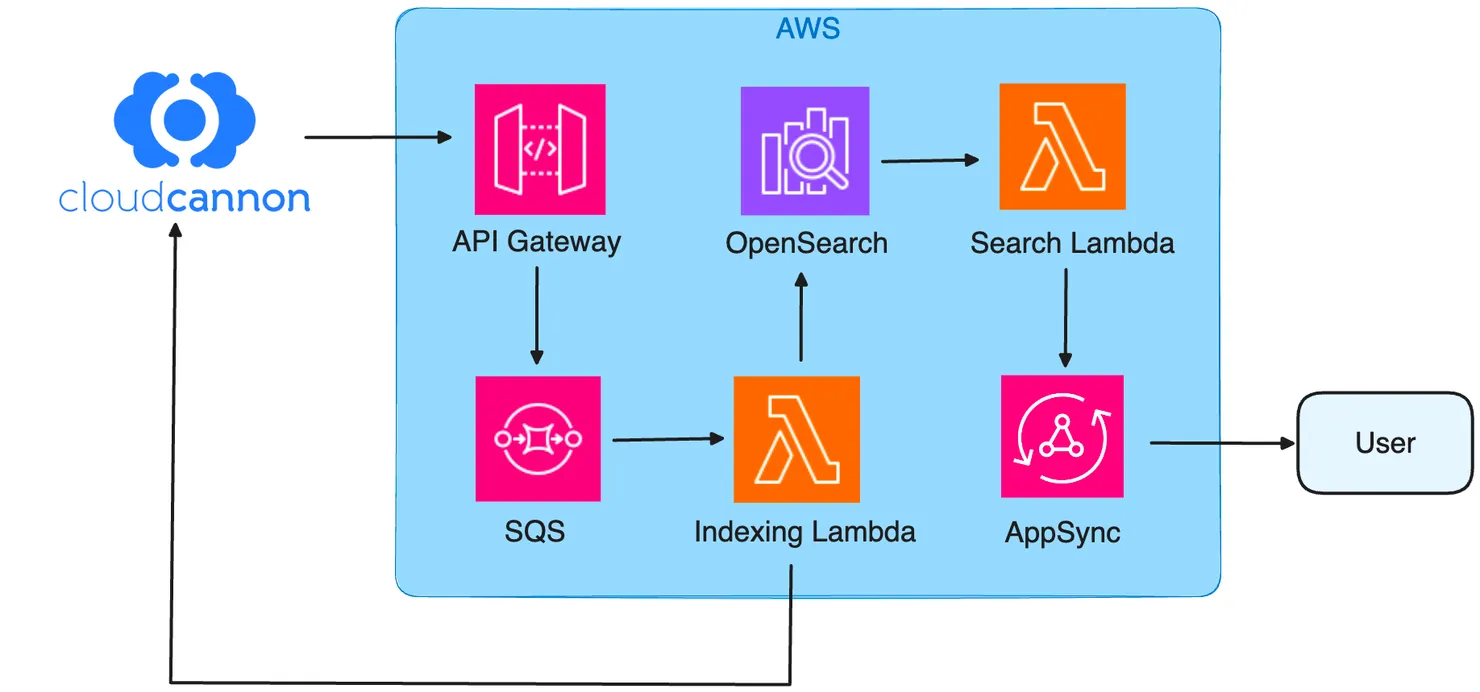
Let’s get into the reason you clicked on this article, Search. At this point I will get into the high-level design and will go into more detail in the sections below. Here is a diagram of my approach.
3. Deep Dive into the Architecture
Integrating OpenSearch into a CloudCannon CMS setup requires a thoughtful approach to data management. The key is to efficiently manage the flow of data across the entire pipeline. There are multiple strategies to consider:
- Bulk Push: Sending all your data in one large push from CloudCannon to OpenSearch. This method can be easier to implement but may cause significant data traffic and increase lead time to getting content to the user.
- Incremental Updates: This method involves sending individual requests for each new or updated recipe. Each request will be a separate message in the SQS queue. In this case the lambda is lightweight with the sole job of taking the data from the message and directly inserts the data into the index.
- Bulk Trigger: (The approach used in this case) Only sending the index name across the pipeline. The Lambda has the context to request all updated data from CloudCannon. This strategy focuses on minimizing data traffic, then performing a bulk indexing of all available content.
3.1 OpenSearch Setup
The foundation of this architecture is an OpenSearch domain. Given the focus on Infrastructure as Code, here’s an example setup using the AWS CDK.
import { EbsDeviceVolumeType } from "aws-cdk-lib/aws-ec2";
import { Domain, EngineVersion } from "aws-cdk-lib/aws-opensearchservice";
import { StringParameter } from "aws-cdk-lib/aws-ssm";
import { Construct } from "constructs";
import { buildResourceName } from "helpers";
const OPEN_SEARCH_DOMAIN_ENDPOINT_PARAMETER = "OPEN_SEARCH_DOMAIN_ENDPOINT";
const OPEN_SEARCH_DOMAIN_ARN_PARAMETER = "OPEN_SEARCH_DOMAIN_ARN";
export class OpenSearchDomain extends Construct {
public domainEndpoint: string;
public domainArn: string;
constructor(scope: Construct, id: string) {
super(scope, id);
const domain = new Domain(this, buildResourceName("domain"), {
version: EngineVersion.OPENSEARCH_2_11,
ebs: {
volumeSize: 10,
volumeType: EbsDeviceVolumeType.GENERAL_PURPOSE_SSD_GP3,
},
zoneAwareness: {
enabled: false,
},
capacity: {
multiAzWithStandbyEnabled: false,
dataNodes: 1,
dataNodeInstanceType: "t3.small.search",
},
});
this.domainEndpoint = domain.domainEndpoint;
this.domainArn = domain.domainArn;
new StringParameter(this, buildResourceName(OPEN_SEARCH_DOMAIN_ENDPOINT_PARAMETER), {
parameterName: buildResourceName(OPEN_SEARCH_DOMAIN_ENDPOINT_PARAMETER),
stringValue: this.domainEndpoint,
});
new StringParameter(this, buildResourceName(OPEN_SEARCH_DOMAIN_ARN_PARAMETER), {
parameterName: buildResourceName(OPEN_SEARCH_DOMAIN_ARN_PARAMETER),
stringValue: this.domainArn,
});
}
}
This configuration sets up a basic OpenSearch domain compatible with AWS’s free tier offering (as of the time of writing). It uses a t3.small.search instance for data nodes, which is a cost-effective option for small to medium-sized datasets. More Info
Key Aspects to Consider:
- Scalability: Ensure your OpenSearch domain can scale as your data grows. Consider using larger instance types or adding more data nodes as needed.
- Security: Implement security measures like access control, firewalls, and encryption to protect your data.
- Monitoring and Maintenance: You may want to monitor your OpenSearch domain for performance and health. One way to do this is to set up alerts for any critical issues.
3.2 SQS & API Gateway
In this configuration, Amazon SQS plays an important role in managing and queuing indexing operations. By leveraging SQS, we can handle the asynchronous queue of each indexing task coming from the CloudCannon builds. This is useful when dealing with high volumes of content updates. This queuing system ensures that no task is lost or overlooked, even during peak loads.
Additionally, setting up a dead letter queue (DLQ) is a good practice. The DLQ captures any indexing requests that fail. With this, issues can be isolated and failed tasks can be investigated without disrupting the ongoing operations, ensuring data integrity.
For those looking to implement a similar setup, the AWS Serverless Land website is a great jumping off point. This guide provides a step-by-step approach to getting started with SQS and integrating it with other AWS services.
AWS API Gateway was also used in this setup. This was chosen primarily for its ease of use and seamless integration with AWS services. It acts as a reliable endpoint for the CloudCannon post-build script. It facilitates automated interactions with the AWS architecture, in this case, triggering the indexing process in SQS.
3.3 Indexing Lambda
This architecture utilizes two key Lambda functions: one for indexing data and another for reading it. The indexing Lambda function, in particular, is designed to execute two critical tasks:
- Remove Deleted Data: The function first eliminates any data associated with the provided deletion IDs.
- Bulk Indexing: It queries CloudCannon for all current content and performs a bulk indexing operation.
Here’s a closer look at the indexing Lambda function:
import { defaultProvider } from "@aws-sdk/credential-provider-node";
import { Client } from "@opensearch-project/opensearch";
import { AwsSigv4Signer } from "@opensearch-project/opensearch/aws";
import { SQSEvent } from "aws-lambda";
import { INDEX_NAME } from "constants/cms";
import { getEnvVariable, getRegion } from "helpers";
import { getIndexData } from "helpers/getIndexData";
import { parseSearchIndexRequest } from "helpers/parseSearchIndexRequest";
// Handler for updating the search index in response to SQS events
export const updateSearchIndexHandler = async (event: SQSEvent) => {
// Parse incoming SQS messages to extract search index requests
const searchIndexRequests = event.Records.map((record) =>
parseSearchIndexRequest(JSON.parse(record.body))
);
// Set up the OpenSearch client with AWS credentials and endpoint
const hostname = "https://" + getEnvVariable("OPENSEARCH_ENDPOINT");
const client = new Client({
...AwsSigv4Signer({
region: getRegion(),
getCredentials: () => {
const credentialsProvider = defaultProvider();
return credentialsProvider();
},
}),
node: hostname,
});
for (const searchIndexRequest of searchIndexRequests) {
const { index } = searchIndexRequest;
console.info(`Updating index '${index}'`);
// Retrieve IDs of deleted records
const deletedIds = await getDeletedIDs();
// Get bulk data for indexing
const bulkBody = await getIndexData();
// Perform bulk indexing operation
const response = await client.bulk({ refresh: true, body: bulkBody });
if (response.statusCode !== 200) {
throw new Error("Failed to upload data");
}
// Delete records from the index as needed
for (const id of deletedIds) {
console.info(`Deleting record '${id}' in index '${index}'`);
const response = await client.delete({
index,
id,
});
if (response.statusCode !== 200) {
throw new Error(`Failed to delete record '${id}'`);
}
}
}
return "ok";
};
export { updateSearchIndexHandler as handler };
This code outlines the process of handling search index requests from the SQS queue, updating the OpenSearch index, and managing deletions.
The getIndexData function is crucial for handling the communication with CloudCannon. In the build process within CloudCannon, two key files are generated to facilitate data synchronization:
- Updated Recipes Data: This file contains all the information related to newly added or updated recipes.
- Deleted Recipe IDs: This file maintains a list of IDs corresponding to recipes that have been deleted.
The data from these two files help ensure that the OpenSearch index remains up-to-date and accurate.
import { INDEX_NAME, CMS_URL } from "constants/cms";
import fetch from "node-fetch";
import { Recipe, recipeSchema, deletedIdSchema } from "types/recipe";
// Constants for CloudCannon paths to get updated and deleted recipes
export const CMS_UPDATED_RECIPES = "/updated_recipes.json";
export const CMS_DELETED_IDS = "/deleted_ids.json";
// Function to fetch and validate data from a given path using the specified schema
const fetchAndValidateData = async (path: string, schema: any) => {
// Fetching data from CloudCannon
const response = await fetch(`${CMS_URL}${path}`);
if (!response.ok) throw new Error(response.statusText);
// Parsing JSON response
const jsonData = await response.json();
// Validating data against the provided schema
const formattedData = await schema.validate(jsonData);
return formattedData;
};
// Function to get all updated recipes
const getAllRecipes: () => Promise<Recipe[] | undefined> = async () => {
return fetchAndValidateData(CMS_UPDATED_RECIPES, recipeSchema);
};
// Function to get index data for OpenSearch
export async function getIndexData() {
const recipes = (await getAllRecipes()) ?? [];
// Create entries for each recipe to be used in bulk indexing
const recipeEntries = recipes.flatMap((recipe) => {
return [
JSON.stringify({ index: { _index: INDEX_NAME.ALL_CONTENT, _id: recipe.id } }),
JSON.stringify(recipe),
];
});
return recipeEntries;
}
// Function to get IDs of deleted recipes
export const getDeletedIDs: () => Promise<string[] | undefined> = async () => {
return fetchAndValidateData(CMS_DELETED_IDS, deletedIdSchema);
};
3.4 Query Lambda
The Query Lambda is designed to search through the index based on given search parameters. It provides users with the information they’re looking for.
The code below takes in the query arguments and executes them across all fields within the index. Thankfully OpenSearch does the heavy lifting by returning any exact or related search results.
import { AppSyncResolverHandler } from "aws-lambda";
import { INDEX_NAME } from "constants/cms";
import {
initializeOpenSearchClient,
mapSearchResults,
validateSearchResults,
} from "helpers/openSearchHelper";
import { QueryGetContentSearchResultsArgs, SearchableRecipe } from "../../../../shared/types/api";
type SearchResultsHandler = AppSyncResolverHandler<
QueryGetContentSearchResultsArgs,
SearchableRecipe[]
>;
// Handler function to get search results
export const getSearchResultsHandler: SearchResultsHandler = async (event) => {
const searchEvent = event.arguments;
// Construct the query for OpenSearch
const formattedQuery = {
query: {
multi_match: {
query: searchEvent.searchString, // The search string input
fields: ["*"], // Search across all fields
},
},
};
// Initialize the OpenSearch client
const client = initializeOpenSearchClient();
// Execute the search query on OpenSearch
const response = await client.search({
index: INDEX_NAME.ALL_CONTENT, // The index to search in
body: formattedQuery, // The search query
});
// Map the search results to a more usable format
const searchableRecipes = mapSearchResults(response.body.hits.hits);
// Validate and return the formatted search results
return validateSearchResults(searchableRecipes);
};
export { getSearchResultsHandler as handler };
3.5 Post build script
CloudCannon offers the flexibility to run scripts both before and after the build process. To utilize this feature, you need to create a .cloudcannon folder in your project’s root directory. Inside this folder, you can place two scripts: prebuild and postbuild. Here’s an example of my post-build script written in Bash:
echo "postbuild script running"
echo "Indexing scripts running"
node ./scripts/index-recipes.js
The index-recipes.js script acts as a trigger to start our search indexing. It is responsible for providing our API Gateway the index name to update the OpenSearch. If we take a look in the scripts folder, we can see the index-recipes.js looks like this:
// Data to be sent in the POST request
const data = {
index: "all_content",
};
// Configuration options for the fetch request
const options = {
method: "POST",
headers: {
"Content-Type": "application/json",
// Authorization header using an env variable which is defined in the API Gateway
Authorization: process.env.INDEX_AUTH_TOKEN,
},
body: JSON.stringify(data, null, 2),
};
// Make a fetch request to the provided API Gateway URL and process the response
fetch(process.env.INDEX_GATEWAY_URL, options).then((res) => res.json());
4. Conclusion
Whether you’re new to CloudCannon or AWS, or an experienced developer looking to expand your toolkit, this integration opens up a world of possibilities for efficient content management and search capabilities. By following the steps outlined in this article, you can set up a system that not only meets your current needs but also scales with your future requirements.