Working with a Third-party Provider, Three Lessons I Learned to Reduce the Lead Time
Vicard Du17 min read

For two years, I worked as a web developer with an investment bank. One of their key aims is to digitalize their finance system in order to speed up the procedure.
At this moment the company was developing a more stable third-party API to provide the core data and which could manage the required performance for all of its consumers.
Unfortunately, the new third-party service ran into a slew of issues. One of them was stability, and it’s one of the most annoying, especially since the entire app depends on it.
The more reliant you are on a third-party service, the less control you have over your app. This suggests an increase in lead time when developing a feature or fixing an issue that is dependent on a third party.
This page is about what the team tried and what we were successful at. But also where we failed to save time with our provider in order to deliver a defined quality to the consumer.
From how we started :
From the start of the project, we had a third-party owner in our team. His objective was to prepare :
- the migration of our core data,
- the connection to the third-party provider APIs,
- and ensure that everything worked flawlessly once completed.
However, he left the project for a new adventure before we obtain the agreement for the migration. I volunteered to replace him. Everything was pretty well-prepared and documented, and I only needed to follow the process.
But, the first weeks we plugged into it, we checked almost all the problems that you can ever have with a provider :
✔️ Availability
✔️ Data integrity
✔️ Breaking change in business rules
✔️ Endpoint performance
Every day, we accumulated more and more problems, and we didn’t know when we will see the end. The time spent asking for investigation or fix increased drastically.
From these issues, I learned how to shorten the time to make a request done and make issues disappear.
My First Lesson: Become aware of your problems before treating them
With experience, we reduce the investigation duration. However, switching context caused me to be less efficient in delivering the features.
So I approached my IT lead and asked him, “What can I do?” His first answer was, “Do you realize how much time you spent on the third party problems?”
Based on this question, I set a board where I record the request frequency, the time spent, the author, and the topic. The result was, in 20 days, I spent 255 min to treats 22 requests.
This board also sheds light on two typical causes :
- Poor communication
- Lack of autonomy
What I learned here is: that referencing all the out-of-context time, gives you a much clearer idea of how much time you spent on it, thinking about the issues, and will push to set up some actions.
So let’s tackle the causes now!
Second lesson: Making a request needs communication and negotiation
Knowing how to communicate the needs to the provider is a thing I learned and still learning in this project.
Making an efficient request is not only about how clear you ask it. It’s also about the information you provide to your interlocutor to convince them to prioritize your request. For that the information should be relevant to help him evaluate the work needed and to commit faster.
Identifying the interlocutor
To save time, asking for a request from the right person avoid doing some back and forth to relay information.
So, identifying the positions of the provider team is the first thing I did.
My next action was to define with the provider an owner for each case/field. Since what I learned was, that putting ownership in only one person will «empower» and lead him to put more effort to solve your request.

An example was, I sent a request to the whole provider team to investigate why we couldn’t create any company. The answer I obtained was, “it’s not us it’s another team”.
I then asked a developer who treats most of the time with them, the owner of the authentication process.
The time to find the right owner took us 2 hours because he was not a part of the provider team. The fix, once we found the owner, took 10 minutes to update the API key.
Know each other :
It happened pretty often that when it comes to explaining problems after investigations from our side or the provider side, it’s hard to understand because :
-
we don’t know the architecture of each other systems,
-
each team uses their abbreviations,
-
we work differently.
A good idea from one of our lead tech was to clarify all these points:
-
Share the architecture of the application,
-
Ask each time the definition of an abbreviation that we don’t understand, but also we use the less abbreviation possible, and only the ones that everyone knows.
-
Ask how they do something if it takes longer than we expect.
Knowing their architecture, and how they work will make us understand the problematics, help us communicate more efficiently, and finally unlock situations faster.
The importance of building a clear request :
What we learnt then was: it’s crucial to prepare your request.
This mean that the request has :
- a clear why
- accessible materials
- a measurable goal
With a clear request, you will make your provider understand better your needs, you’ll have less work to do, and it will be harder for them to refuse it facing facts.
A clear request is also a way to respect your provider. Advice from our sensei to make an even better request is to formally ask your provider to refuse the request if it’s not perfect.
This is the best way to learn how to create the perfect interface for your specific relationship.
It is essential that to respect the provider the same way you respect your customers.
The importance of the explaining the impact
What I often did before was in a hurry, ask them to investigate a problem, but without explaining to them the impact
What could happen is that they don’t answer. They are busy and let you request again, to be sure that it’s important, or they would take their time.
Here is a typical example I could do :
– We have a problem, the private individual creation endpoint is on timeout, could you investigate on it?
In this example, the provider doesn’t know the emergency level and will put the minimum effort to answer this.
After several failures, my lead tech told me to learn the standard of the company to do a good request.
The previous request became then :
– We have an emergency problem right now, 10000 customers cannot create their account on the production environment, because the private individual creation endpoint doesn’t work since 14h. Could you investigate, please?
Here you have a clear impact. It helps your provider to understand the emergency of your request and to prioritize it.
Make it faster : Bring the material
To reduce the time to convince our provider to help us, or to achieve a fix, I needed to prepare my talk and material. This help the provider to localize and take decision faster.
There are plenty of tools that help us to gather all important information to prepare our requests to the provider. Here are some that we use :
-
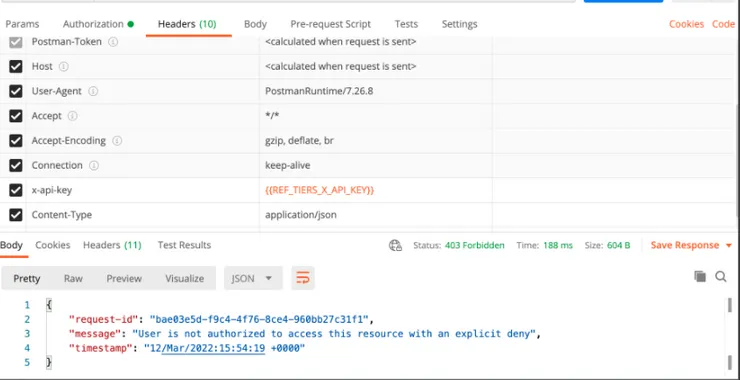
Rest API client to test your provider APIs (Postman / RestClient):
- What we do if their endpoint doesn’t work is to send them a screenshot of our Postman call, with the environment, URL, headers, body, response code, and response body visible. Your provider could extract more data from your screenshot than you imagine and can guide you.
-
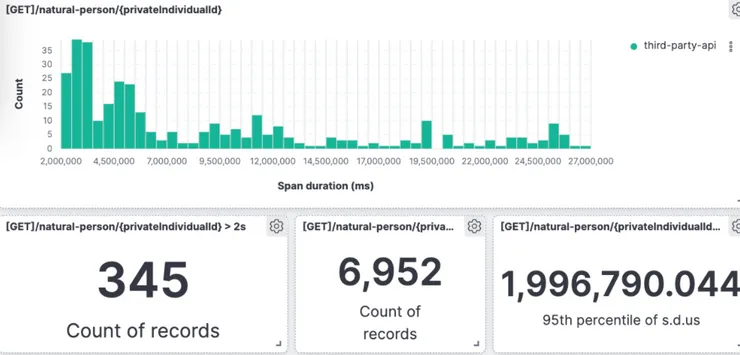
Monitoring tools (Kibana, Datadog, …):
- These tools allow us to visualize and analyze our application logs through different aspects like histograms, charts, … We will see how essential it is below.
-
Sharing workspace for sharing documentation or joint action (Notion:
- What we do with this tool is a sharing board where we track the current or future problems that could impact our provider or us. We put significant information that helps us to track the progress and to define the priority to treat them.

-
Draw schema (Excalidraw, whimsical) :
- Explain problems, architecture or workflow with a drawing allow a better understanding. It makes easier to localize the problem, and to evaluate the time to fix it. Good advice that I learned was to draw with your customer/provider during a meeting help to synchronise your understanding of a problem.
-
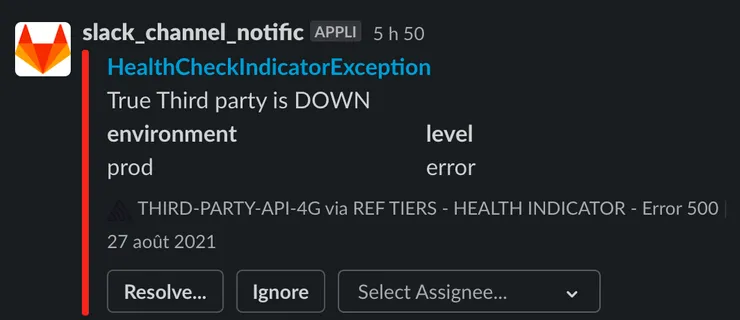
Alerting tools (Sentry + Slack):
- To save time, and not be constantly checking our monitoring tools, we set a notification alert for each time something goes wrong from our provider server. This will help us to react faster, and to mention the problem to our provider. With this process, it happened that we detected the problem earlier than our provider.
Establish good quality criteria/KPI
One day, the provider, announce to us that they are preparing for critical data migration.
The risks if it is not done correctly can have impacts on :
- data integrity ⇒ if you provide the wrong data, you lose the trust of the customer
- performance of their SQL queries/ endpoint response time ⇒ a slow app (3 second to answer) can decrease 53% of your customer
- and the availability ⇒ If you have international customers, your apps need to be available 7/7 and 24/24, and you must inform your customer when there is any maintenance
At this time, I was not confident to ask our provider for a guarantee that the process will work without any negative impacts.
So I asked for help from our “sensei”. He made me realize that I was not confident because we didn’t have any good criteria to which the third party is committed.
But what are good criteria?
Good criteria should be:
- clear to make it easy to remember to constantly have it in mind
- measurable to determine if it is reached, or if you will reach it soon
- accessible with checkpoints to be able to check it at any time
- realistic to be reachable
To define our criteria, our first step was to collect all problems that we encountered and sort them to have a map of the actual situation.
From this information, we could define a clear plan on what to measure.
Monitoring, monitoring, always monitoring … and master your tools
In the beginning, we were monitoring the liveness of our provider endpoint by coding a scheduler that calls all the endpoints every 5 min and registers the endpoint state in our database. That was not a great idea.
The result was poorly shareable for everyone, and we needed to layout the data to make it understandable, which took way too much time. We even deactivated it, because it created too many logs.
Another bad idea was to monitor all the routes, by calling them several times to make an aggregate of the response time.
We got the results, but it was manual and painful to do it frequently.
We then asked our sensei for help again, and he made us realize, that we already have all the tools that we needed, but we didn’t know how to master them.
To avoid all these pains and to save some time, we spent 2 hours studying our monitoring tools.
We were then able to automatize the monitoring by defining the duration of a single event in our code (a span), and using our monitoring tools (Kibana) to display these events in a form of a dashboard.
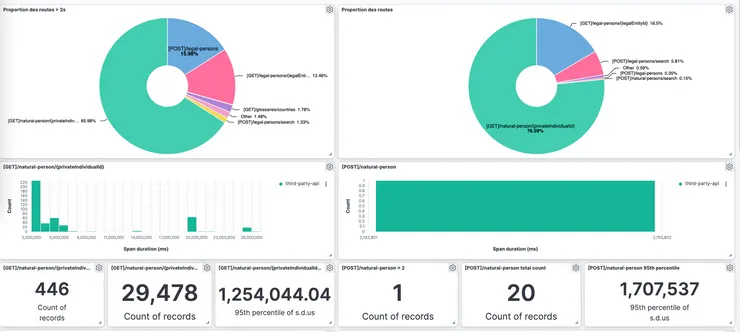
After getting the performance monitoring data in an accessible form, we came to our sponsor with some checkable numbers to tell them that we were not confident about the migration if they could guarantee us that 95% of their endpoints response time are below 2sec.
This made them aware that they were not ready with some facts.
The impact was big. It results in our provider’s PM coming to us to make an official communication that they had to delay the data migration, this in front of our sponsor.
Use monitoring to measure the KPI and to negotiate with your provider
Here is another example of how monitoring helps us to convince our provider, with minimum time.
Every time we encountered a data integrity problem we asked our provider to modify the data, but nothing will stop that if it happens again.
We needed to find the root cause, and some long-term solution to prevent it from happening again.
How? By gathering the material, we visually showed them:
-
how often does the problem occur
-
how much time both of us spent
-
how much time we could save.
With this information, we reconciled our interests (not having bugs anymore) with their interests (not having to waste time on hotfix frequently) and proposed a “win-win” situation.
We then convinced them to work together to find the root cause and fix it by adding a business rule in their code.

Using visual management helped us to have much more impact to negotiate with our provider to investigate the root cause instead of fixing the problem temporarily. We then never heard about the problem again until now.
Now commit!!
We saw how to do a great request, but still, something is missing.
The last point is to make your provider commit to it. A good commitment, has a confirmation message, with a check date and an identified owner.
So you know when to check and know who to talk with when the request is still not resolved.
Go further
Go drink a beer … or a tea with the provider team :
A thing that we didn’t achieve was to invite the provider team to a bar.
This is not a joke. We could figure it out that they are probably not so different from you.
This could also make us aware of their working environment, and how they work, and so better interact together.
Third lesson : Share your tools and methodologies
Another important lesson, that I learned during these years was how to avoid overwhelm when I was in front of tons of requests from others teams or our providers.
What I learned was to delegate the request but not anyhow.
I aimed to make everyone a copy of myself when it comes to the method and knowledge of my topic.

Teaching to make everyone autonomous will release your stress, gain time, and last but not least, put your footprint on the methodology. So even if you leave, people will work as you do.
In this paragraph, I will tell you how I made things work as I was present, and not to be overwhelmed with my problems.
Make your team autonomous
Help your team to identify the problem
5 different teams, depending on us to get the provider data.
In the beginning, we got contacted multiple times a day for data reading or writing problems.
However, the provider data could be recomputed with many business rules set by others teams through different layers.
To overcome this situation, we helped everyone to identify the origin of the problem. For that, we set a status error (424) with a message containing the problem, when the problem comes from our provider.
Since that, the contact frequency reduced drastically and the teams became much more compliant.
Help your team pay attention to the provider problem
Previously I showed you that alerting tools can be great to gather material and be notified if something goes wrong.
But there is also a drawback that we experienced by not mastering it.
What we didn’t do well, was logging our error. The alerting tools caught all the error logs, which some of them were not, and sent too many false positive notifications.
The consequence was that we became immune from it, and we didn’t pay attention to the notifications.
So it is important to set up well your alerting tools and your log to make everyone use it.
Monitor your requests
In my first lesson, I learned to monitor all the requests, and the result was in 20 days I spent 255 min to threatening 22 requests.
So what did I do then?
I sorted all the requests and realized that most of them are easy to solve.
What they required is to know in which endpoint they could find the specific information they needed.
The problem was no one was familiar with these endpoints, and there is no easy way to get the information.
To solve this, I made a Q and A, postman collection, and documentation relative to the most frequent requests, to make everyone autonomous.
The 255 minutes dropped to 10, with 2 requests. Finally, I had some time to drink a coffee!
So teaching the team is time-consuming, but it’s a great investment in the long term.
If you work 6 months on the project, I let you count how much time you gain, and what you can do with that?
Make your provider autonomous in front of problems
A typical problem that we encountered was the increasing response time each time they did a deployment, for different reasons.
This leads us to always check the response time of all of their endpoints, after each deployment. It took us 30 min each time.
To avoid this, we shared our monitoring response time tools with them with the endpoints that we used the most.
It cost us 30 min to create an access login and to teach them how to use it.
With that, we are pretty confident, that they will be more aware of the impact of their deployments and fix it if necessary.
And this would make them also more reactive since they are committed to the response time that they need to deliver.
The result is that our provider, check frequently the dashboard, and contact us by themselves to tell us that they improved the response times of some endpoints which were already less than we expected.
Don’t miss any requests : track it with a co-board:
When it comes to new version deployment or data migration, to follow critical request resolution, we created an exclusive channel during important events.
But it would be counterproductive to create many channels for smaller requests, like data/logs analysis.
What we tried was to implement a light Kanban board (we used Notion for that) to track progress, and don’t forget any of them. This board could be filled by the problem owner team.
It is also useful to track the weekly/monthly meeting with the provider if you couldn’t attempt it.
To be honest, our first try doesn’t work. Our provider told us that they will have a hundred consumers and couldn’t maintain a board like that, if they have to do it for every one of them.
What we are planning to do is to maintain it at the beginning by ourselves, to track the requests that we needed to ask again, and the time spent. This will give us some material to determine if we should convince harder our provider to use it.
Invest into long term by teaching
There are two ways to put your footprint on a project:
- you work a lot, it’s worked, hurra everyone will congrats you 5 min. However, you lost your hair and the problem should be fixed well, because the day you disappear, I let you imagine the rest of the story.
- you are pretty smart (or have a good sensei), you teach everyone little by little a routine about how you do to deal with the provider. The day you disappear, everything is still working as you were here. You succeed to put your footprint on this ownership. People will work as you teach them. So you can enjoy your vacation.
Conclusion
What I can retain from all of these experiences was, that there is always a way to make things done by becoming proactive.
It’s not easy, and it’s time-consuming. But, you should not think about losing time, but investing time for the long term.
To sum up what I’ve learnt over this project:
-
Communicate clearly your request to the right interlocutor with a why, materials to only post it once with respect, and expect them a commitment.
-
Monitoring the most sensible “points” and making them accessible, would make you gain a bunch of time to prepare your request, and convince your provider to prioritize it.
-
Before looking for new tools or coding some new ones for monitoring, look at what you already have, and master it, it can be better than what you expect.
-
Make everyone autonomous to decentralize your task. This avoids you from switching contexts, and put your footprint on the methodology. The project will still work even if you disappear … at the coffee shop.
… And last but not least don’t forget the drink with your provider, it’s important to drink!


