AWS Fargate: harness the power of serverless for long-running computational tasks
James Haworth Wheatman11 min read

TLDR: We all know the advantages of serverless computing: pay only for what you use; scale up and down with ease; abstract away the complexities of managing servers. In this article, I illustrate how you can acquire these benefits for long computational tasks which are too large for Lambda or Google Cloud Functions to handle. I share a case study from a recent project and how we used AWS Fargate (along with S3, Lambda, DynamoDB, and more!) to create a robust task architecture.
Recently, a client approached us with a state-of-the-art modelling system which had been designed by industry-leading domain experts. The techniques used in the modelling software meant that, for its use-case, the software could run simulations in an order of magnitude less time than the competing solutions.
Despite being an industry-leading scientific model, the delivery of that solution through software was holding the product back from its full potential. The software interface was a Python GUI and was distributed as source code directly to users. The model could take hours to run and if it failed (often due to invalid input), the modeller would only discover this error on returning to the program after several hours away, only to correct the error and rerun the test case. Often, multiple variations need to be simulated, however the desktop application couldn’t execute multiple runs concurrently (as the software is limited by the processing power of the machine it runs on).
The mission
We wanted to bring this software to the market as an industry-leading product in terms of scientific modelling and software engineering. We would leverage cloud services to mitigate some of the disadvantages of the desktop implementation.
Here are some of the main things we wanted to add to the current functionality of the model:
-
Improved distribution by migrating to the cloud:
- Easier on-boarding (no software installation - just login).
- Improved security (no user access to source code).
- Run the model from any computer.
-
Increased scalability:
- Execute multiple model runs concurrently to save users’ time.
-
Improved user experience:
- More data validation rules to prevent failed model runs.
- Email notifications for when the model has completed a run.
The challenge
The abstract problem to solve was that we had a 500,000-line black-box program that was tightly coupled to the environment and file system of the machine it was running on. In our case, three issues stand out:
-
The model code is tightly coupled to the modeller’s development environment - it calls
os.systemin many places to run shell commands on specific libraries (these included dependencies on GNU Fortran - not something you see in your everyday web application!). -
The model code is tightly coupled to the modeller’s file system - it creates intermediate output files to save data between different steps in a run. This decision was initially made from a scientific standpoint - a modeller might want to check some intermediate output - and had stuck as a design pattern across the software.
-
The model code has significant complexity, and re-engineering it came with risks to the validity of the results.
These constraints meant that we needed:
-
To run the model code on a system with the same environment as the modellers’ computers.
-
A way to persist intermediate files in the cloud between different runs.
The strategy
The high-level flow of a modeller executing a model run would go like this:
-
The modeller goes to the web application from their browser and configures a new run. Parameters that they configure are saved to DynamoDB and input files they upload are saved in S3.
-
The modeller clicks the “execute” button for a specific task, which triggers (a Lambda to trigger) a task in Fargate. This spins up a Docker image registered in ECR with the correct environment and source code to run the model. The task name is passed in as an environment variable.
-
The task pulls the correct input files from S3 and the user-defined parameters from DynamoDB.
-
The model task is then executed as it would be on a modeller’s local computer.
-
The model syncs the resulting output directory to S3 and EventBridge and SES are used to notify the user of the status of the run via email.
The architect of the project drew a handy architecture diagram to illustrate exactly how we achieved these steps and I’ll go through the steps that we took along the way.
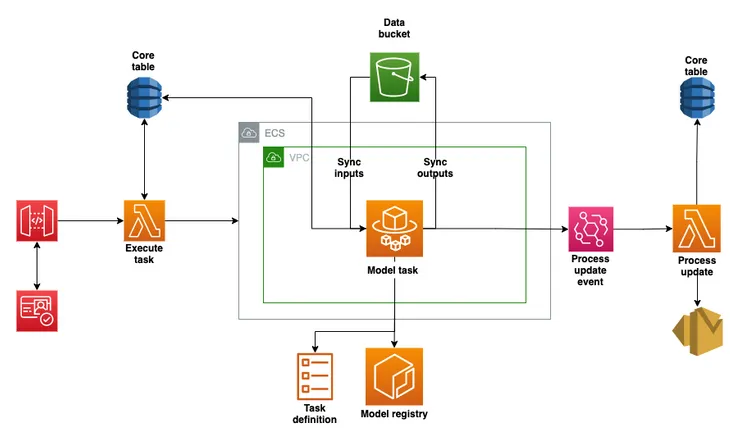
Dockerize the tasks: Fargate + ECR + VPC
The first step was to create an environment to run the model; Docker was designed to solve this very problem (“well, it worked when it ran on my computer!”).
A new container was defined and the required dependencies for the project were resolved (we used Poetry to manage the Python libraries).
We used Docker volumes for the project so that any intermediate files created within the container are synced with our outer file systems to inspect and validate. A docker-compose.yml file was also written to simplify bringing the container up and down and passing in environment variables from a .env file.
There are several discrete tasks that the model can run, each one generating different output files. For our use-case, we would have a single Docker image, which contains the model code for every type of task - the task to be executed would be defined as an environment variable (a container is designed to be brought up with a single purpose, then taken down once the task is complete).
Now that we know the task we want to execute, we can define the functions we want to run for each task. We define a TASK_DEFINITIONS variable which stores handlers for each task: preprocessor, executor (where we will run the main task), postprocessor, and failure (the model can be temperamental to user input, and we need to handle failure explicitly). I will come back to the pre- and post-processors in the next section.
The executor is simply a function which makes a call to the model source code to execute the desired task. This means we can define an env variable - TASK_NAME - and run the model locally by accessing bash from within the container:
docker-compose up -d
docker-compose exec <image-name> bash
python main.py
Note: my local machine doesn’t have the correct dependencies to run the model code, but the container that I run on my local machine does.
The container can now be migrated to the cloud so that the model code can be accessed from anywhere in the world without the need to manually distribute the source code.
The image is registered with AWS Elastic Container Registry (ECR) where the container can be stored and accessed (Model registry in our architecture diagram). A Virtual Private Cloud (VPC) is configured to accept requests to trigger an AWS Fargate task.
Fargate is “serverless compute for containers”; this means that our container isn’t running in the cloud when we don’t need it - AWS handles the provisioning of resources to “spin up” a container from our image at the moment we want to run a task. This means that we are only paying for what we use whilst still having the potential to scale ad infinitum (we can trigger multiple tasks concurrently and AWS will just spin up more instances for us in the cloud). The one drawback of this architecture is that Fargate requires some time to build the container when we request for our task to be run (this was around a minute for our (large) container).
You can see Fargate (Model task) sitting at the centre of our architecture diagram within the VPC in ECS.
We also set up Cloudwatch to create logs for each run to help us and the modellers debug issues with the model.
Syncing input and output directories: S3
Until now, the model works in the cloud so long as the required input files are present in the file system of the Docker image; however, input files are specific to the context of a run, and if we want to get meaningful output then we need to pass in the correct input files at the point that we execute a task.
For each task, a new instance of the image is spun-up, so any intermediate files are lost when the container is pulled down and the context is lost (this is fine, as we want different executions to remain distinct from each other).
We set up an S3 bucket to store the inputs and outputs of tasks, which means that the files which we expect to persist between different tasks can be synced between permanent storage from task to task.
Each task was saving its output to a different directory, so within our TASK_DEFINITIONS, we define an input_dir, from which we would pull the contents from S3 and a number of output_dirs to which we would push the output of the model. These outputs might be downloaded by the user or used by a different task as input files. This syncing of files happens in the preprocess and postprocess of each task.
Data model: DynamoDB
As well as input files, the model also depends on a range of input parameters that the user can define. In the desktop app, the program gets these input parameters by reading and parsing a local file called INPUT_PARAMETERS.txt.
Each model run entity has a corresponding entity within a DynamoDB table (in practice there are multiple types of entity available for the user to manipulate). The database follows the single-table design as described in The DynamoDB Handbook by Alex DeBrie and uses dynamodb-toolbox to model entities. The user can interact with these entities via the web application to set properties of the run.
We created a corresponding manager in the dockerized model code for each type of entity in the database (e.g. RunManager) which can get the entity and also perform simple updates on text fields (set error messages etc.). The entity is retrieved from DynamoDB which then overrides the variables which were previously being retrieved from INPUT_PARAMETERS.txt, which otherwise describes a generic run.
The model is now no-longer dependent on a local file for input of discrete parameters; but how does the user configure those variables to get a final valid output to their desired parameters?
Web Application: Lambda + Next.js
It’s now time to plug the main pieces together.
We developed a Next.js frontend to interface with the remote model. This comes with all the advantages of developing UI using technologies that were designed to handle UI (i.e. not Python!). This meant our input methods were more interactive and our outputs more visual, as we were able to leverage existing libraries.
We added validation rules to the inputs (with warning messages) to prevent the user running the model with parameters that don’t make sense. We accept input files as upload fields of several forms, which are pre-processed to validate that the values in the files were within the expected range before uploading to S3.
We built our backend REST API using AWS Lambda. As with Fargate, Lambda offers flexible scaling, has a nice integration for the back-office tool we created in Retool, and we didn’t mind the infamous cold starts for our use case.
Another advantage of using Lambda was that we can use AWS CloudFormation (infrastructure as code solution) to provision our infrastructure from a serverless.ts file which defines all the resources required for an environment. If we wanted to create a new environment, running sls deploy <env-name> would provision the resources defined in the file instead of needing to interact with the AWS console.
Notifying model outcomes: EventBridge + SES
Until now, a specific model task can be triggered to run in the cloud where it will sync the relevant input files, pull the correct input parameters, run the task, and sync the output files back to S3. Finally, we need to notify the user of the outcome of the model (success + results/ error + logs).
In the model, we defined a RunEventsManager which could send an event via AWS EventBridge when the postprocess or failure handler was completed in the model. We added a Lambda in our backend which was triggered by an EventBridge event (because we were using CloudFormation, we just needed to define the event that triggers the lambda in serverless.ts).
When an event occurs, the Lambda uses AWS SES client to send an email to the user, which notifies them immediately when they can check their results - there’s no need to come back to check that the model hasn’t failed every 15 minutes anymore!
Summary
Using the described architecture, we had delivered a significant improvement to the user experience in running scientific modelling tasks by bringing the software to the cloud and affording it all the advantages of a serverless implementation.


