Hasura: GraphQL Without the Baggage.
Mo Khazali14 min read

Spoiler Alert: Star Wars references below. Proceed at your own risk…
The introduction of GraphQL back in 2015 garnered a lot of hype in the development sphere - allowing clients to describe exactly what data they require (preventing over-fetching unneeded information) and unifying multiple resources into a singular request. This substantially improved scalability and reusability of backend endpoints, and makes the development experience all-in-all more pleasant.
So you might be thinking to yourself: “Great. What’s the catch?”
Well… Implementing GraphQL into your backend will inadvertently increase complexity - you’ll need to dedicate time on defining types, efficient resolvers, mutators, queries, etc. If you’re working as a full-stack developer, you might find that using GraphQL is kind of like taking a dollar from one pocket and putting it in another. The added complexity can start to outweigh the benefits, especially on smaller scale projects. On top of that, caching is complex with GraphQL. With no in-built caching capabilities, this often becomes a pain point for developers.
That’s not to diminish or underplay the clear benefits of using GraphQL.
However, I want to use this opportunity to touch on some of the less talked about vices of GraphQL, and present Hasura as a possible solution to some of these concerns. Hasura is a GraphQL service that automatically generates GraphQL endpoints from your database schemas, taking out a lot of the complexities and manual work needed. Simply by connecting Hasura to your SQL database, it will generate schemas and resolvers using the existing tables and views. It’s quite magical in how quick it is to get up and running…
GraphQL Complexities
Boilerplate & Initial Setup
As you’ll usually find with most other large scale dependencies or libraries, the addition of GraphQL will require some level of initial setup and boilerplate, you’re adding a new layer to both your frontend and your backend. You’re probably going to need to add a GraphQL client, define the types, schemas, error handling, caching on the frontend level. On the backend side, you’ll need to define multiple resolvers to fetch different views of the data (get all the data/get a single datapoint with an id), as well as defining mutations for creating new datapoints, editing existing data, and deleting data.
Now you could argue that these would all still be required if you used normal REST endpoints - and you would be right. However, on top of these, you’ll need to deal with typing on the backend, caching (you can’t rely on native HTTP caching like REST APIs), higher order components, and additional validators to catch some edge-cases that arise from defined schemas.
A solution commonly taken on the backend side, is to define boilerplate abstractions to take the repetition out of having to define basic resolvers/queries for new data classes you add into your application, but again this takes time to setup (plus you’re adding more complexity). While this might not be an issue for larger projects that can reap the benefits of using GraphQL, it becomes a massive swaying point away for small projects.
Resolver Hell
Resolvers are the functions that resolve the values for any field in a schema. They can return primitive values, or objects that get further broken down into more primitive types. You’ll find that these typically return values from databases or other APIs.
Now there are a number of databases and ORMs that come with GraphQL mappers that will automatically handle resolvers for you when you are defining your data in objects. For example, in a project that I worked on, we use GORM, which handles resolving and schema generation. However, these do come with their overheads, and you would need to define your data models according to these data access tools.
In many cases you’ll find that you’re dealing with your database directly, and you’ll be doing the DB querying yourself. This opens a whole new can of worms to deal with.
A common issue that many face is over-querying the database. Let’s demonstrate this with an example:
You are creating an application to manage a large movie cinema company with multiple branches. You have a query that fetches a list of all the cinemas, the screens in each, the movies showing on each screen, and which production companies released them.
Now presume that there are 5 cinemas (branches), with 10 screens each, each playing 5 movies at any given point. This means that we have 1 query to get the cinemas, 5 queries for each cinema getting the screens, and 50 queries for the movies playing on each screen (50 calls to get the details of the movie playing on each screens). That comes down to a total of 56 database calls for this query.
Say you wanted to fetch some basic metadata about each of these movies as well (such as the production companies), that would be another 50 database calls added, which would increase our total to a whopping 106 database calls…
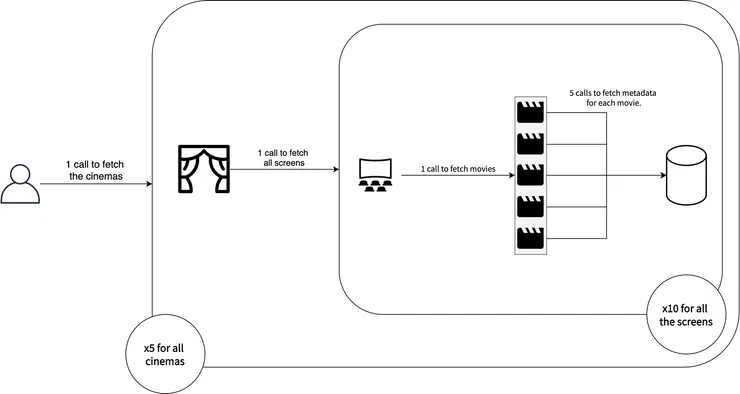
Cinema example above visualised.
This can be mitigated by strategising and coming up with efficient queries and resolvers, but the problem remains that it is very easy to fall into these common patterns that will result in overfetching. It’s just the price that comes with allowing the client to specify their data needs and schemas.
There are solutions to deal with this - for example, Dataloader will batch some of these database calls together and cache some of the results. However, these solutions are far from perfect and they have limitations when making certain queries. Not to mention that by adding new dependencies, we start inadvertently increasing complexity of the application.
Performance & Caching
With complex views on the data, comes the cost of query complexity and the number of database calls increasing. It becomes a balancing game… You’ll want to use GraphQL’s ability to define graph-based traversals to fetch multiple resources (in fact, this is probably the single biggest selling point IMHO), but use it too much (or irresponsibly), and you might find that your queries become slow and start to massively affect performance.
Take the Star Wars example that is shown on the homepage of the GraphQL website:
type Query {
hero: Character
}
type Character {
name: String
friends: [Character]
homeWorld: Planet
}
type Planet {
name: String
climate: String
}
Let’s try and visualise it with a flowchart, with the main trio of the original series. If Luke Skywalker is the hero of the original series (which is a false statement, because we all know the Ewoks were the true heroes), he has several friends, and each of these friends have a homeWorld.
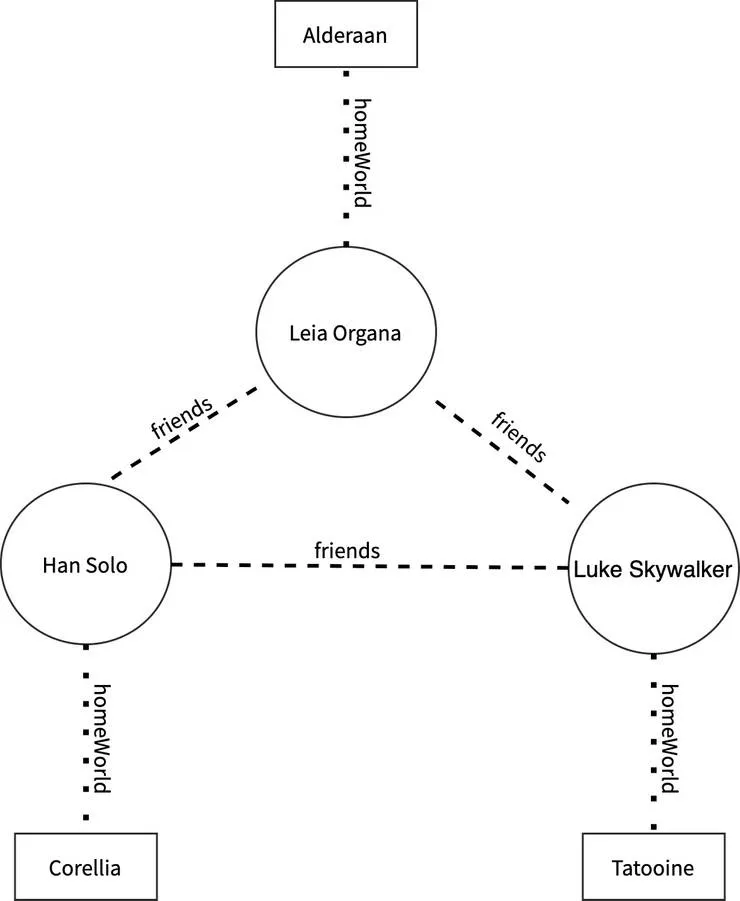
GraphQL allows you to traverse the graph of Characters by defining resolvers to fetch the friends. Now this is a fairly simple example, and you’ll find that real world data will usually have more complex relations and hence this graph will become larger. This will take a toll on performance, and you may find that certain queries will take unreasonably long to run.
A common approach taken to solve this problem is through caching, and although it won’t work well for frequently changing data, this can help reduce the number of queries that need to be made regularly on data that rarely changes.
As an example, Apollo can allow you to define and control caching structures on your web applications, but if you have multiple frontend applications (say a web, Android, and iOS app), you’ll probably need to handle caching on each of these levels separately. Again, added complexity that will be introduced by using GraphQL.
However, this options is only viable for data that isn’t changing regularly… So in the case where Leia’s home planet of Alderaan gets obliterated by the Death Star, or Han Solo and Leia become separated (ergo are no longer considered friends) due to their son falling to the dark side of the force, you may find that caching will result in data inaccuracies. This is where the importance of having well-written and efficient resolvers and database calls comes into play yet again.
And with that, all may seem lost, but from the darkness of caching, boilerplate, and complex resolvers comes the saving grace of Hasura…
Hasura

Hasura is an open source service that allows you to take your relational databases, and automatically generate GraphQL APIs on top of them. Effectively, this removes one of the biggest challenges that backend developers using GraphQL face, which is creating efficient SQL queries and resolvers.
Looking at the challenges posed above, the issue of excessive boilerplate code & high initial costs effectively become neutralised by using a tool like Hasura. I had a Postgres database running on my machine, and it took me a total of 15 minutes to spin up Hasura with Docker. Just by changing the docker-compose, I pointed it to my database, and it loaded up already connected and hosting a GraphQL endpoint with my defined views! Honestly, it felt like some form of vodoo magic!
The steps I followed were really quite simple:
- Fetch the docker-compose file with
curl. - Run
docker-compose up -d - Get yourself a cup of coffee while you wait for it to run.
- Open the console page at
localhost:8080/console - Click on the data tab, and click the “Connect Database” button.
- Add a name for your database, the SQL flavour, and lastly the database URL.
- Click the connect button.
- After it’s done connecting, click on the “GraphiQL” tab, and see that your database tables can be queried out of the box!
Now, a common question that may come up about the initial cost of using a technology is how well it integrates with existing codebases. Presume that you’re already using a GraphQL endpoint for the backend of your application, and you want to incrementally introduce Hasura to handle the basic queries and subscriptions (yes, it comes prebuilt with subscriptions, and that can be an absolute pain with certain GraphQL servers). You can use a feature called Remote Schemas to point Hasura to your already existing GraphQL endpoint, and it’ll automatically combine the schemas together to create a unified GraphQL endpoint that your frontend can use. Additionally, you can use this to delegate more complex business logic in your code to other services (such as a payment API).
The second challenge touched on above was the issue of inefficient and complex resolvers. Without getting into much detail, Hasura compiles down GraphQL queries using abstract syntax trees, validates and checks permissioning at this level, and then constructs the entire query into one raw SQL query. On top of this, they do 2 levels of caching (one at the SQL compilation level, and another at the database level with prepared statements) within their architecture to reduce the amount of times these compilation steps are required. They’re building and improving on this architecture and performance with every update. For example, they’ve introduced JSON aggregations on the database level, effectively removing the need to flatten the results from the database calls in the backend - they claim this increases performance anywhere from 5-8 times! For those who are interested, they have an interesting article on their website talking about their architecture in more detail.
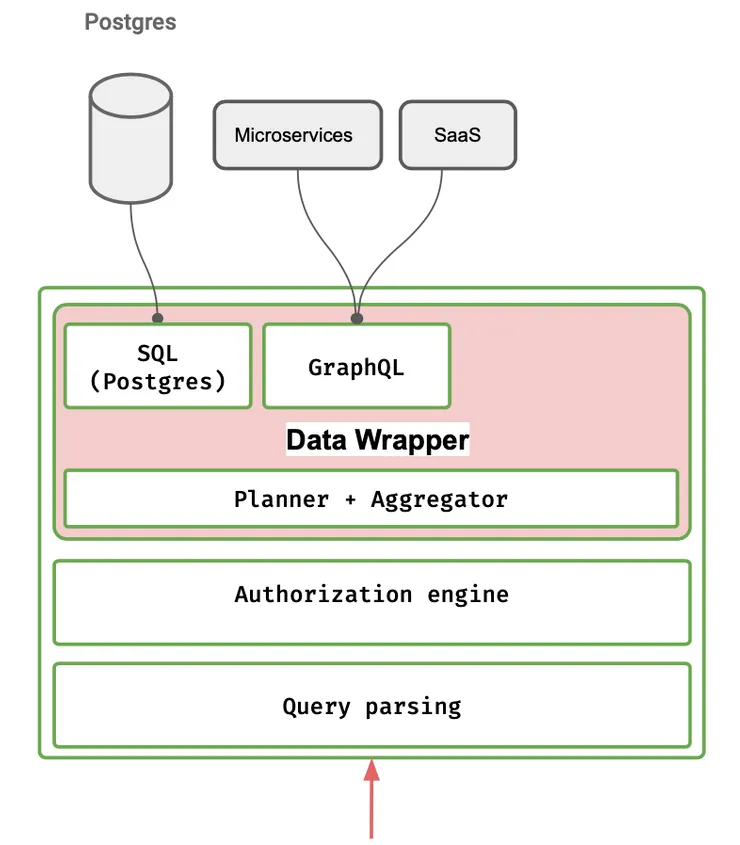
Hasura’s Data Wrapper (Source: hasura.io)
Lastly, we touched on the issue of caching & performance. Within the data wrapper layer, there’s already 2 levels of caching that will significantly improve performance. Additionally, there is another layer of caching, which is on the query level, that effectively allows you to cache the response being sent back to the client for a defined period of time. You can make a call with the @cached directive to cache the response, supplying an optional ttl argument (how long to cache the response):
query MyCachedQuery @cached(ttl: 120) {
users {
id
name
}
}
This caching comes working out of the box. In contrast to common caching approaches (such as using Apollo), having this caching done on the server side can be beneficial for unifying the responses on any given platform at any point of time. Imagine you have a cached query for the top players in a leaderboard. If the caches are set at different points on the client, there may be inconsistencies in how this data is displayed. Caching on the server-side circumvents this.
On top of that, Hasura’s performance isn’t only due to compiled queries, efficient resolvers and caching. There’s a ton more work put into improving speed and performance and it is a regularly improved and maintained project that’s already heavily utilised in the industry.
So to demonstrate the Star Wars example we saw above, I went ahead and created a database schema to have the following tables:
- Character
- Planet
- friendsWith
I did all of this through the Hasura data admin panel (sort of like a lite version of PGAdmin). Through this data panel, you can choose which tables/views can be tracked by the GraphQL schema, and you can define table relationships and how they manifest in the GraphQL schema.
Switching to the “GraphiQL” tab, we can now see that the explorer now has a bunch of different datapoints:

You can fetch the list of each of the data types by calling the basic data type (for example, Planet), and this comes with pagination and filtering out of the box. Alternatively, if you’re looking for some form of aggregation on the data, you can use the _aggregate datapoint, which can run some basic aggregation on the data (such as averaging a field, counting, finding the min/max the field, or even getting the standard deviation). Lastly, you can get a single data entry by using the by_pk variation.
Now, to see this in action, we construct a query asking for the first character in our character table. We ask for the name of the character, their home planet (along with its associated climate), and a list of their friends.
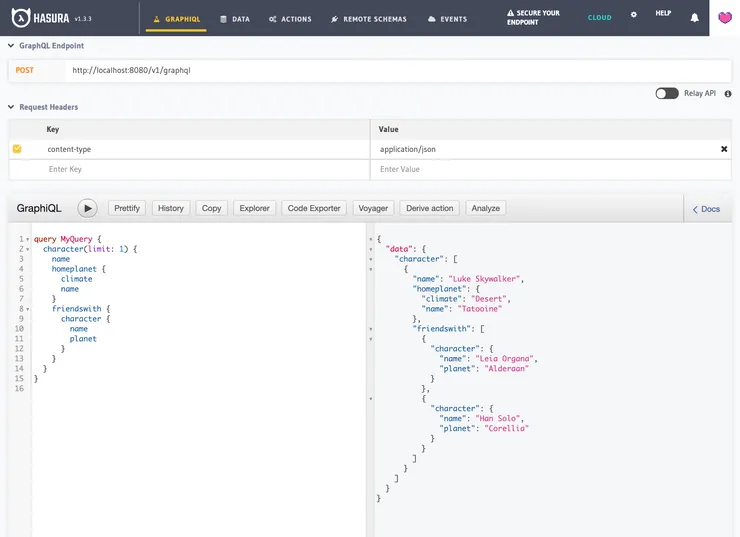
To be able to do this in the matter of a couple minutes is something that I still find magical.
I’ll end here with some of the selling points that I think make Hasura really shine:
- Automatically generates the schemas and resolvers for your GraphQL endpoints (less pain).
- Comes prebuilt with option variables that you can use in your queries (for example,
limitandoffset, which will allow you to more or less handle lazy loading of datapoints). - Currently works with a number of SQL databases (Postgres, Microsoft SQL, Amazon Aurora, and Google Big Query) with more coming soon.
- Easy to integrate with authentication and permissioning platforms, such as Auth0.
- Gives you a web UI to manage the GraphQL endpoint, as well as an interface to manage the database and its views itself (think PGAdmin).
- Using Remote Schemas, you can hook Hasura up with other GraphQL endpoints and other services to unify your endpoints.
- Using Actions, you’ll be able to define calls to custom handlers that will execute more complex business logic (which opens the door to serverless by using Lambdas)
- You can define event triggers to call actions automatically (when a user signs up, send an email via a Lambda function).
- Highly maintained and used by the community, with over 23k stars on Github and 250m+ downloads.
Conclusion
GraphQL provides some fascinating functionality that aims to make the data layer of applications unified and flexible. As with most things, this comes at a cost. The initial setup and boilerplates will mean that you will need to spend time upfront in creating the right infrastructure for using GraphQL. On top of that, the flexibility in schema means that you will need to have additional considerations when it comes to performance, and you will need to come up with efficient queries and resolvers. Lastly, with GraphQL we lose the native HTTP caching capabilities, meaning that caching is not standardized and becomes cumbersome additional work.
Hasura, acting as a service layer between your databases and clients, can automatically generate performant GraphQL queries, mutators, and even subscriptions, with minimal effort on the your end.
Whilst Hasura’s solution to automatic generation of schemas and endpoints might not offer the full flexibility that large-scale highly complex applications might need, it opens the door to using GraphQL on smaller scale projects where the startup costs of introducing it would outweigh the benefits. I believe this is where Hasura will excel, and where it will ultimately find its place in the GraphQL market.


