How to Prevent Springboot Crashes after a Checkout
Clément Robin5 min read

At Theodo, I’m working on a project where we need to start 5 APIs simultaneously where 40 developers are continuously pushing new lines of codes and our stack is relying on Spring Boot. Unfortunately one of our favorite action during our daily dev routine is just crazily complicated: 10% of the time, checking out from a branch to another one break the build of our APIs. It’s a real pain point and we lose hours in debugging for something that is not a bug!
My problem is: How to checkout smoothly without worrying about API compilation being different between branches?
TL;DR
This script composes the post-checkout hook to automate how to cleanly restart your Spring Boot APIs:
#!/usr/bin/env bash
IFS=$'\n\t'
WORKDIR=$PWD
PREVIOUS_HEAD=$1
NEW_HEAD=$2
APIS="
users-api
payment-api
mailing-api
"
for nameApi in $APIS;
do
cd ./$nameApi/src/
GIT_DIFF=$(git diff $PREVIOUS_HEAD...$NEW_HEAD --relative)
cd $WORKDIR
if [[ ! -z "$GIT_DIFF" ]]; then
if [[ "$(docker-compose ps $nameApi | grep Up)" ]]; then
rm -rf ./${nameApi}/target
docker-compose restart $nameApi
else
rm -rf ./${nameApi}/target
fi
fi
done
What happens when you checkout?
Let’s take a simple example; I have to review the code of feature_branch_2, I thus have to jump often from feature_branch_1 to feature_branch_2.
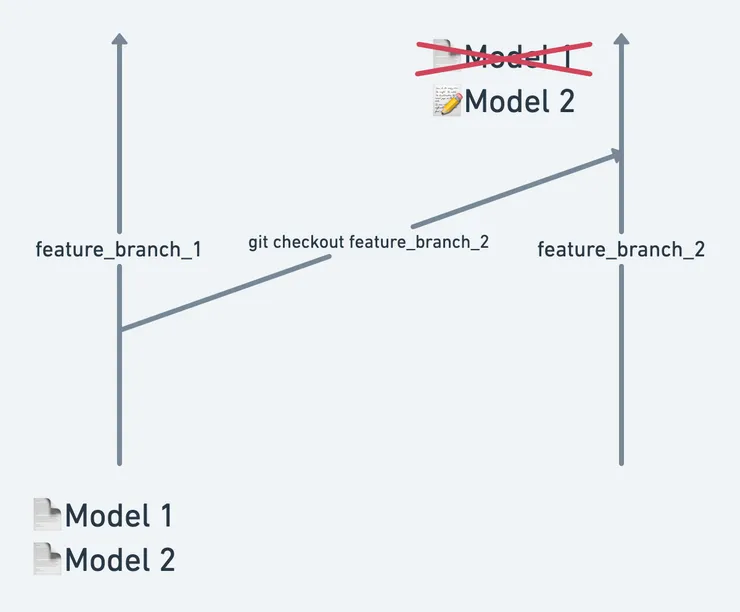
The diagram above illustrate the differences between the 2 branches :
- Model 1 doesn’t exist in the second branch
- Model 2 has some changes between the two branches
During the checkout, the change of branch can be brutal for Spring Boot and the automatic reloading does not manage to notice all the changes. Some of them may be missing from the compiled files and the server may crash.
My team was using a trick to circumvent the problem, it was performed through 3 painful operations :
- Stop the server
- Clean the builded target files
- Rebuild the docker image and start the server (rebuilding the docker image included a target files build)
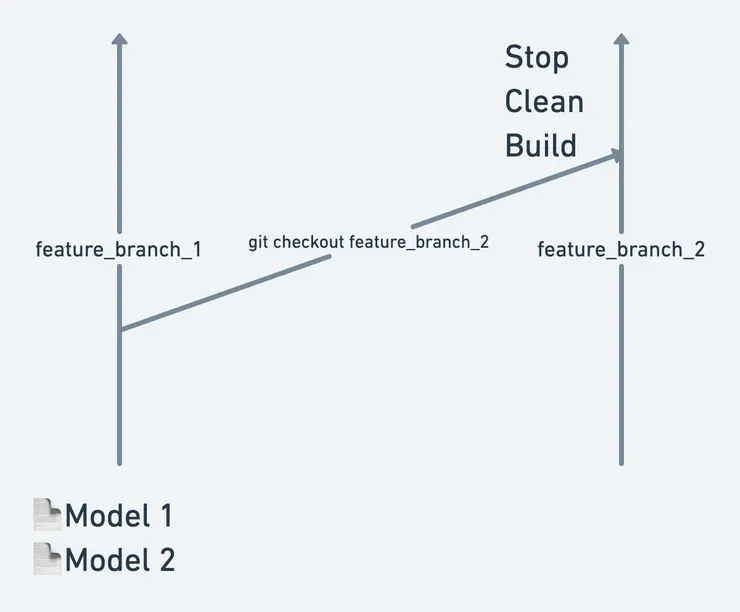
After some tests, we optimized the first and third step and only had to do the following :
- Clean the builded target files
- Restart the server
We reduced the number of steps but who wants to do 2 (if not 3) commands like this at each checkout?
How to automate this routine?
The best way I chose to automate was the post-checkout action that is native in Git versioning system. The idea is simple, after each checkout, a bash script is automatically executed based on the difference between the start and end branches of the checkout. This script is the following:
#!/usr/bin/env bash
set -euo pipefail
IFS=$'\n\t'
WORKDIR=$PWD
PREVIOUS_HEAD=$1
NEW_HEAD=$2
APIS="
users-api
payment-api
mailing-api
"
for nameApi in $APIS;
do
cd ./$nameApi/src/
GIT_DIFF=$(git diff $PREVIOUS_HEAD...$NEW_HEAD --relative)
cd $WORKDIR
if [[ ! -z "$GIT_DIFF" ]]; then
if [[ "$(docker-compose ps $nameApi | grep Up)" ]]; then
rm -rf ./${nameApi}/target
docker-compose restart $nameApi
else
rm -rf ./${nameApi}/target
fi
fi
done
The idea is to execute the clean and the restart for each API of my application, only if the sources’ files from one branch to another contain differences.
The clean allows for a clean start of the API whether it is up or down. Additionally, I restart the API if it was already up before the checkout!
To make this script working on your project, you just need to copy/paste it in a file named .git/hooks/post-checkout.
What about the first lines?
I got into the habit of starting my bash scripts with the
set -euo pipefailoption allowing it to stop at the correct line if there is an error. It’s easier to debug if required.Also, the variable
IFS=$'\n\t'allows the terminal to set the internal field separator.
To go further
The major problem with putting your script in the .git folder is that you can’t make the most of Git to version and share it with your whole team. Indeed, this folder is often ignored in the repo and has no history. In fact someone else in the team brilliantly discovered the Husky library. With this library, you can put your script in a versioned folder (let’s call it scripts at the root of your project) and configure Husky to call it whenever you want (let’s say at the post-checkout event obviously). You can then have this type of configuration in your package.json:
{
...,
"husky": {
"hooks": {
"post-checkout": "./scripts/post-checkout-hook.sh $HUSKY_GIT_PARAMS"
}
},
...
}
And if you want more with the Git hooks, there are plenty of other applications. For example, you can use the pre-commit hook to run the linter and format the code before sharing it with others! How many times had we changed a few things in a file and the saving started formatting everything because the previous developer who worked on the file didn’t set up the IDE’s linter…
You also can deal with other hooks proposed by Git, Reynald Mandel made a great example of post-merge hook use.
So what?
To talk about the limits, the script is executed each time we checkout and if the git diff resulting in a huge number of files, the execution can use a lot of memory. Just not that it’s limited by the architecture of the script, we actually don’t check each file, we just check if there is a difference or not.
Finally, with this hack, I reduced the frustration of the developers in the team, and we gained 40 hours of work per week at the scale of all the team (40 developers). This also represents the sobering saving of a developer on our client’s bill!

