An introduction to DynamoDB data modeling
Alexandre Pernin16 min read

I discovered DynamoDB a few months ago, in the context of a very high traffic web application built using the Serverless Framework. DynamoDB - as well as Single-Table design - was fairly new to me, and I quickly noticed that there are a few concepts to grasp before designing the first data models. This article aims to provide a beginner-friendly tutorial for developers who are considering starting a project with DynamoDB, or who are just curious about this technology.
DynamoDB is a fully managed NoSQL database released by AWS in 2012. As the other main NoSQL solutions, such as MongoDB (2009) or Apache Cassandra (2008), it was designed at a time when storage prices were low compared to those of processing power. In the seventies, when relational databases were first introduced, this relationship was inverted. In particular, high storage prices gave incentives to limit storage needs by avoiding data duplication. You would design separate entities and put each one of them in a separate table, which drastically simplifies the data modeling exercise. You could then simply write the entity-relationship diagram (ERD), translate it into tables and retrieve the information of your choice by joining tables together.
With a NoSQL database such as DynamoDB, the join functionality does not exist, you’re invited to put all your entities in the same table. This is the concept of Single-Table Design. By removing joins, you write more efficient queries, which reduces the needs of computing power. However, this comes at a cost: the data modeling exercise is slightly more complicated. The entity diagram does not give you the model anymore. The ways your application will interact with data - the access patterns - are now a key building block of your modelisation.
In this tutorial, I will take the example of a sample book review website. On the application, users can write a review for a book of their choice. They can also read the reviews written by others on any given book. Finally, users can read all the reviews written by a given user. As a bonus, we will talk about sorting these reviews in ante-chronological order.
Start from an entity-relationship diagram
The starting point of the exercise is the ERD. We won’t need any joins here, which are the reflection of relationships between entities, but having these relationships in mind is necessary to know how you’ll make it work without them.
In our case, the diagram is quite simple. There are 3 entities: books, users and reviews. There is a one-to-many relationship between users and reviews (a user can write several reviews), and another one-to-many relationship between reviews and books (a book can be reviewed several times). In this case, reviews implicitly represent the many-to-many relationship between users and books.
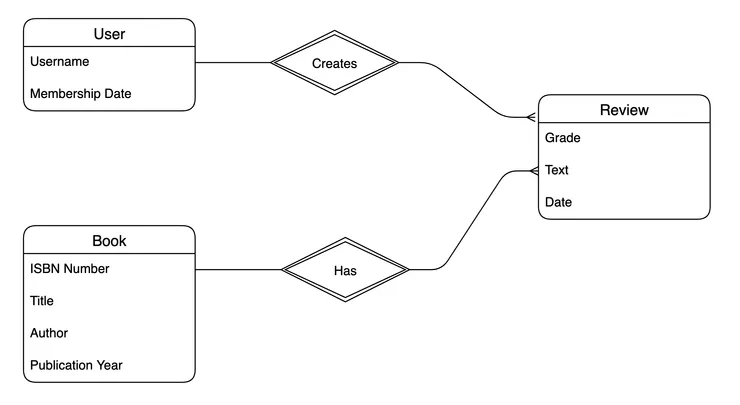 Entity-relationship diagram for users, books, and reviews.
Entity-relationship diagram for users, books, and reviews.
As described on the diagram, we use the ISBN (International Standard Book Number) as a unique identifier for books, and the username for users. A review consists of a date, a grade, and a text.
Write down the access patterns
Before any attempt to model the keys in your table, you should write down the access patterns of your application. The modelisation’s purpose is to handle all of them. It is important to be thorough in this step, or you might be unable to retrieve some information from your table. For the purpose of this exercise, let’s consider three of them.
| Access Pattern |
|---|
| Get all the reviews for a given book |
| Get all the reviews for a given user |
| Update a review |
On the book page, we need the reviews for this particular book. On a user profile, we will query for the reviews written by this user. Finally, we will see how we would update a review.
Model the structure of the primary key
Once you have defined all of your access patterns, you can start the modelisation. The primary key is a core concept in DynamoDB, and almost the single piece of structure imposed to your table. It is thus at the core of the modeling exercise.
DynamoDB allows two kinds of primary keys:
- Simple primary keys, made of a single element called
partition key (
PK). - Composite primary keys, made of
partition key (
PK) and sort key (SK).
The partition key is particularly important, as it represents an identifier of the server on which the data actually is (also called a storage node). Two items that have distinct partition keys will thus be difficult to query together.
The primary key related rules are simple:
- A table must have a primary key
- All the items in the table must have a value for that primary key
- Each primary key must be unique <> an item is uniquely identified by its primary key
- Each request to READ item(s) must specify the partition key *
- Each request to WRITE an item must specify the full primary key
* Here I intentionally avoid scans, which are 9 times out of 10 bad practice
With these concepts in mind, you can start modeling. For each entity, we have to think about the best partition key and sort key to fulfill all the access patterns. In other words, the goal of this step is to fill the table below:
| Entity | PK | SK |
|---|---|---|
| Book | ? | ? |
| Review | ? | ? |
| User | ? | ? |
A common practice is to start with the top-level entity that has the highest number of relationships. Here, books and users play a somehow symmetric role so let’s start with modeling books.
The goal is to be able to query at the same time for a book and its associated reviews. We thus have to make sure that the book reviews have the same partition key as the book itself, in order for them to be stored on the same physical machine. Using this partition key, DynamoDB will identify the associated storage node in a O(1) time. In DynamoDB terminology, we say that we put the book and its reviews in the same item collection.
Because an item in DynamoDB must be uniquely identified by its primary key, the sort key will be the way we differentiate a book from its reviews. Let’s have a look at the following primary key structure:
| Entity | PK | SK |
|---|---|---|
| Book | BOOK#<ISBN Number> | BOOK#<ISBN Number> |
| Review | BOOK#<ISBN Number> | USER#<Username> |
Prefixing the key by the entity name is a common pattern. It gives us more clarity and compensates for the fact that we put all entities in the same table. The ISBN of the book is here used as a unique id. It enforces the uniqueness of a book’s primary key. Finally, the sort key USER#<Username> allows us to differentiate reviews. It also identifies the author of the review. Implicitly, it says that a given user can not write two reviews about the same book (otherwise it violates the primary key’s uniqueness principle).
Visualize your model in NoSQL Workbench
During the modeling exercise, it is good practice to model out some example data. It especially helps to visualize how a query would respond. The NoSQL Workbench is a great tool for that. At this stage of the modelisation, here is how a simple example would look like:
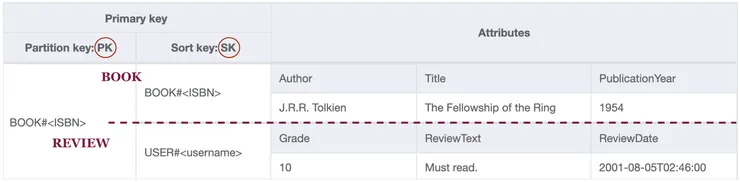 Main index - Books and reviews visualisation in NoSQL Workbench.
Main index - Books and reviews visualisation in NoSQL Workbench.
A row in this table is an item in DynamoDB. Both items share a common partition key, they are in the same item collection and can thus be queried together. We choose generic names for the key attributes (PK and SK) because they do not store the same type of information depending of the kind of entity they belong to.
To solve the first access pattern, just make a request for the items with a PK of BOOK#<ISBN>, with no condition on the sort key (remember that for a READ operation, specifying the sort key is optional). Both items in the table match this condition, so they will be returned together, sorted alphabetically on the sort key. In JSON format, you get something like
[
{
"PK": {
"S": "BOOK#<ISBN>"
},
"SK": {
"S": "BOOK#<ISBN>"
},
"Author": {
"S": "J.R.R. Tolkien"
},
"Title": {
"S": "The Fellowship of the Ring"
},
"PublicationYear": {
"N": "1954"
}
},
{
"PK": {
"S": "BOOK#<ISBN>"
},
"SK": {
"S": "USER#<username>"
},
"Grade": {
"N": "10"
},
"ReviewText": {
"S": "Must read."
},
"ReviewDate": {
"S": "2001-08-05T02:46:00"
}
}
]
Define secondary indexes if needed
Let’s move on to the second access pattern. We want to be able to query for a user and all their reviews. We therefore need the user to be in the same partition as their reviews. But these already share a common partition key with the book they relate to. We thus somehow need the reviews to be in two distinct item collections. This is the notion of global secondary index (GSI).
When creating a GSI, you specify two attributes in your table that will act as a primary key in the secondary index. In other words, this index will be a copy of the data of the main table, in which the primary key is different. Using this, we can have the book and reviews to share a common PK in the main index, while having the reviews and the associated author in the same partition in a secondary index.
In our case, we can then adopt symmetric approaches in the main and secondary index. In the main index, the primary key structure will be like below:
| Entity | PK | SK |
|---|---|---|
| Book | BOOK#<ISBN Number> | BOOK#<ISBN Number> |
| Review | BOOK#<ISBN Number> | USER#<Username> |
| User | USER#<Username> | USER#<Username> |
See that the primary key structure for books and users follow the exact same pattern. In NoSQL Workbench, adding the review author to our example would bring us to:
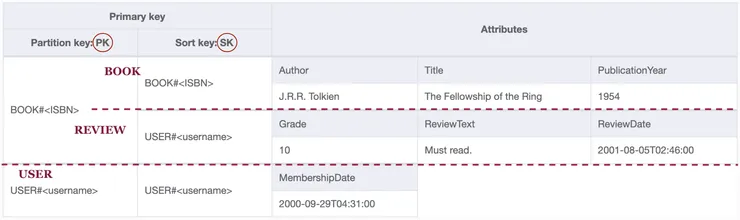 Main index - Users, books and reviews visualisation.
Main index - Users, books and reviews visualisation.
Notice that both the user and their review have a SK of USER#<Username>. Having the SK of the main index as partition key in the secondary one would therefore solve the second access pattern. More precisely, we can just flip the PK and SK of the main index in the GSI. The secondary index in NoSQL Workbench would then be:
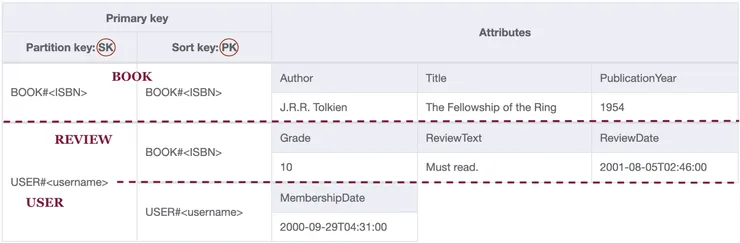 Secondary index - Users, books and reviews visualisation.
Secondary index - Users, books and reviews visualisation.
To solve the second access pattern, we make a request on the secondary index for the items with a partition key (here the SK attribute) of USER#<Username>, with no condition on the sort key. Both the user and the review match this condition, so they will be returned together in an array, sorted alphabetically on the sort key. To retrieve the user first, we can set the scanIndexForward property to false, so that DynamoDB reads the items in descending order. Note that by default (with scanIndexForward property set to true), DynamoDB will send the items in the order they are sorted in the table, which is the ascending order. If you are unsure, just look at your items in the NoSQL Workbench: top to bottom is the ascending ordering used by DynamoDB.
At this stage of the modelisation, most of the work is done. Inserting a review - the third access pattern - is trivial. We use the UpdateItem action of DynamoDB (you can learn more about writing items here), by specifying BOOK#<ISBN> for the partition key and USER#<Username> for the sort key (remember that for WRITE operations you must provide both the partition key and the sort key), along with the other attributes characterizing the review - grade, review text and date. By doing this, you implicitly specify a value for the PK and SK in the secondary index, and DynamoDB will thus take care of updating that item in the GSI as well.
What about sorting?
Sorting the query results before they are sent back to your application can be crucial in some situations. Going back to the book review example, imagine that you want to paginate the reviews for a particular book. More precisely, what if you want to show the 1 to X most recent reviews on the first page, then the X+1 to 2X most recent ones on the second page etc… Without sorting, you would have to retrieve all reviews on each page, and then get rid of those that are not in the appropriate range for that page. This would be very inefficient, especially if your application has a lot of contributors.
Let’s cover how we would sort the reviews in ante-chronological order. As we have seen so far, in DynamoDB, almost everything is achieved using the primary key. It is also true for sorting. If you want a special ordering of the items returned from a query, there is only one way to do so: it has to be done with the sort key. Implicitly, it means that you need to arrange your items so that they are sorted in advance. This again stresses the need for thorough data modeling upfront.
In our case, the sort key thus needs to cary some sort of time indicator. Both unix timestamps (e.g. 744569696) or ISO-8601 date format (e.g. 2021-03-05T18:54:56+00:00) would work. The only requirement is that it must be sortable. Let’s go for ISO-
8601 timestamps as they are human-readable. We can then prefix the sort key for reviews like so:
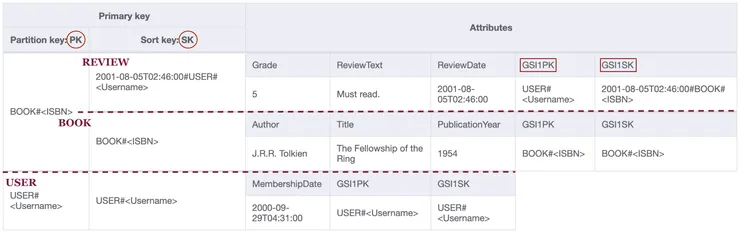 Main index - Timestamped version - Users, books and reviews visualisation.
Main index - Timestamped version - Users, books and reviews visualisation.
For the review entity, the partition key and sort key in the secondary index are no longer an inversion of the primary key in the main table. That’s why we have to add specific attributes to our table. We name them generically GSIPK and GSISK respectively as they do not store the same information per entity. They will act as partition and sort key in the secondary index.
To get a book and the associated reviews sorted, the query is the same as before. Query all the items with a partition key of BOOK#<Username> with no restrictions on the sort key. With the scanIndexForward property set to false, you would retrieve the book and then the review. As DynamoDB orders the items in ascending orders in your table, a more recent review would come after the first one:
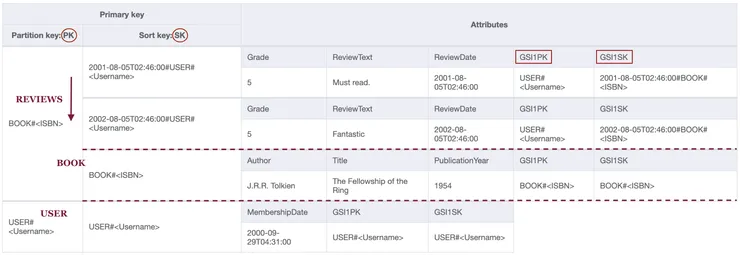 Main index - Timestamped version - Sorted reviews.
Main index - Timestamped version - Sorted reviews.
With the scanIndexForward property set to false, you retrieve the items from bottom to top. This gives you the book and then the reviews from most recent to oldest. Finally, use the limit option (like in SQL) set to 16 for example and you restrict yourself to the 15 most recent reviews.
In the secondary index, the data is structured symmetrically. In this index, the item attributes GSI1PK and GSISK are the partition and sort key, respectively.
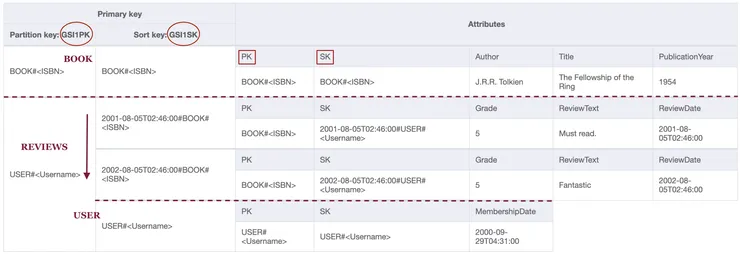 Secondary index - Timestamped version - Sorted reviews.
Secondary index - Timestamped version - Sorted reviews.
A query for items with a partition key (here the GSIPK attribute) of USER#<Username> with no restriction on the sort key gives us the user and their reviews. With scanIndexForward property set to false, the user will come first, and then their reviews in ante-chronological order. The response, in JSON format would be:
[
{
"PK": {
"S": "USER#<Username>"
},
"SK": {
"S": "USER#<Username>"
},
"MembershipDate": {
"S": "2000-09-29T04:31:00"
},
"GSI1PK": {
"S": "USER#<Username>"
},
"GSI1SK": {
"S": "USER#<Username>"
}
},
{
"PK": {
"S": "BOOK#<ISBN>"
},
"SK": {
"S": "2002-08-05T02:46:00#USER#<Username>"
},
"Grade": {
"N": "5"
},
"ReviewText": {
"S": "Fantastic"
},
"ReviewDate": {
"S": "2002-08-05T02:46:00"
},
"GSI1PK": {
"S": "USER#<Username>"
},
"GSI1SK": {
"S": "2002-08-05T02:46:00#BOOK#<ISBN>"
}
},
{
"PK": {
"S": "BOOK#<ISBN>"
},
"SK": {
"S": "2001-08-05T02:46:00#USER#<Username>"
},
"Grade": {
"N": "5"
},
"ReviewText": {
"S": "Must read."
},
"ReviewDate": {
"S": "2001-08-05T02:46:00"
},
"GSI1PK": {
"S": "USER#<Username>"
},
"GSI1SK": {
"S": "2001-08-05T02:46:00#BOOK#<ISBN>"
}
},
]
Wrapping it all up
In this simple modeling exercise, we have set out the key steps that should be followed when creating a data model in DynamoDB. Write your entity diagram to identify the relationship between objects in your application. Carefully write down your access patterns and start modeling the structure of primary keys for your entities. Try to do your best with the main index, and then make the use of secondary indexes if needed. During the exercise, take a practical example and visualize it in the NoSQL Workbench.
Once done, celebrate, as scaling is not a problem anymore. In our example, a new book would represent a new partition, and therefore a new storage node: DynamoDB abstracts the complexity of database scaling from you. Because partitions are split up on different physical machines, and because the time to find the partition you query for is constant, your queries efficiency will remain stable as the amount of data increases.
However, this automatic scaling isn’t free - the modelisation exercise is slightly more complicated than with relational database systems. You can’t just go from your entities diagram to the data model. Access patterns must be thought of in advance, as they should drive the modelisation.
Because of this, there are a few situations in which DynamoDB might not be the optimal choice. If your application is meant to allow for a virtually unlimited number of access patterns - an analytics platform for instance - then DynamoDB will not be a good fit. Or, if you are building a new application from scratch, you may not know how its functionalities will look like in the longer run. It will then be tough to think of all the access patterns in advance. Finally, keep in mind the learning curve. If you plan to build a product as fast you can, and if your team is much more familiar with relational database systems, you might want to stick to it to maximize development speed.
If not in one of these situations, go and try DynamoDB. To speed up learning, I would strongly recommend reading The DynamoDB Book by Alex Debrie. You’ll find plenty of well chosen examples as well as the main theoretical concepts behind it. Enjoy!

