Why Aws Step Functions Is Not the Best Tool for Business Processes
Marin Merlin10 min read

I recently worked on a project where we needed to orchestrate a process, applying for loan to be precise, which could take weeks. To do this, we decided on using a serverless architecture and specifically AWS Step functions. The use of such a framework helped us immensely to organize the flow of the process but it wasn’t without a few bumps along the road. My aim in this article is to warn you about those bumps and help you have a smoother ride. ##I. AWS stacks and their limits
###1. Cloud-formation stack Cloudformation is a service from AWS which allows you to create and manage linked AWS resources (which are themselves other services). All the resources that we used in our project were initially in a single CloudFormation stack. Let’s look at an example of a stack :
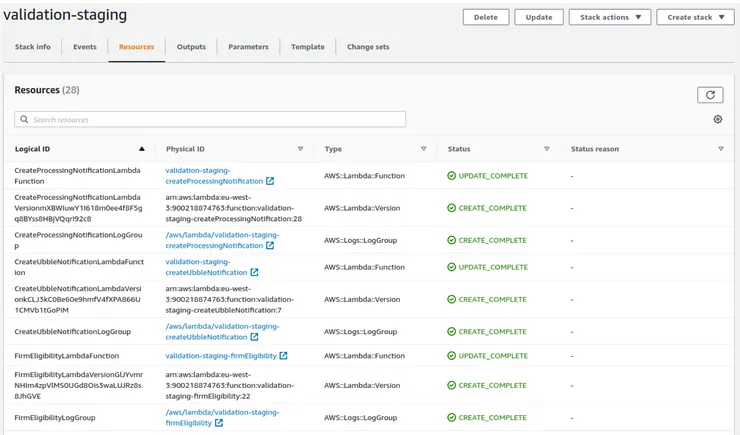
Here we can find our Lambdas, as well as Logs and if we scrolled further we could also find the state-machines we used.
In terms of code, a stack corresponds to a configuration file called serverless.yml. In this file all the resources ,
environment variables, and outputs, are defined.
###2. Cloud formation stacks limits A stack has multiple limits which can quickly be reached. You can find the complete list in the AWS docs but we will only talk about the one encountered in the project.
A stack can contain a maximum of 200 resources. 200 state machines and Lambdas would indeed be a lot but there are other resources we have to take into account. Indeed, for each Lambda we create we also create a Log group resource and a Version resource. State Machines also have a Role resource. There are other resources we use like SQS, S3 buckets, DynamoDB tables. As mentioned above we had all our resources in a single stack. As you can already guess we reached that limit of 200 resources. We were unable to develop any new features until we found a solution to this limit. As such, we were hard-pressed to find a solution.
The first thing we thought of was, is this really a limit? Could our dev ops team set this limit to higher value or could we even contact the AWS support to ask for a less restrictive limit? We tried but to no avail. This limit is one you will have to live with and can’t cheat your way around. Ok, so the quick fix we hoped for is a bust, let’s get thinking about real solutions.
We knew we could split the stack into multiple ones but that would require a lot of refactoring and we already saw glimpses of the problems it would generate. So we searched for a smarter approach and we found a plugin that did exactly what we wanted: serverless-plugin-split-stacks, or so we thought. Three of us tried getting the plugin to work like we wanted without success. But what really made us give up on this solution was that we realised more and more that the real problem was the faulty architecture of our serverless application. Even if we could fix the resource problem with the plugin (if we got it to work) other problems might arise from the fact that we bunched up everything into one stack. So ultimately we decided that the pragmatical solution was to split our stack into multiple sub stacks.
3.Difficulties with concurrent stack updates
I’ll spare you the details of how we split the stack, but we essentially had different services which we put in separate stacks and kept one main stack with nothing more than the orchestration between the different services. You can see in the image below an example of the split works. What I want to talk about here is the new problem brought on by the split.
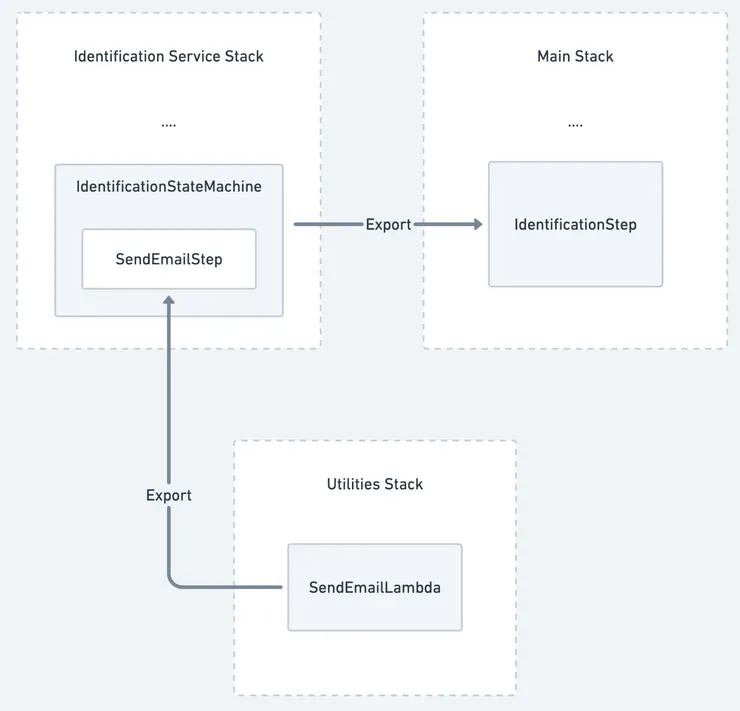
For the split to work we have to export the resources we intend to use in the main stack, namely the different lambdas and sub state-machines. AWS allows us to do this quite easily by defining exports with region specific names that we can then import in another stack. The problem comes when we want to update an exported resource. Before going into more detail you will need to understand how AWS updates a resource. There are two types of updates :
- Updating only the core of the resource, for example changing the code of a lambda
- Updating the configuration of the resource, for example the name of the resource
You can find out more about Cloud Formation resource updates here. In the first case, AWS can update the resource without changing anything but the changes we asked for. In the second case AWS has to replace the resource with a new one. In order to do so, it has to delete the resource and create a new one.
Now we can come back to our problem. What happens when an exported resource needs to be removed to update it? Well AWS won’t allow you to deploy your stack because you will be trying to remove a resource currently used by another stack. Quite the pickle. The only way to go around this is to duplicate the resource, apply the update on the new copy, change the import to use the new copy and finally remove the old copy. We realised this problem existed before we went ahead with splitting the stacks. We wagered that those updates would seldom be needed. I can confirm that a few months later those updates were very rare, and the proposed workaround worked, so all in all it was a good call. I choose to talk about this problem because it brings me to a larger underlying problem: handling versions in an AWS serverless framework.
##II. Problems caused by differences in versions between state machines and lambdas
###1.UseExactVersion The problem we encountered with the limits of the stack brought us to another problem : handling changes in version. For me this problem is at the core of what I want to talk about in this article. We knew of it before but until this point it wasn’t too problematic. Indeed AWS gives us a tool to handle changes in version. For example : what happens when you deploy a new state machine with one lambda updated? Do the old state machines use the new lambda when they get to the step in question?
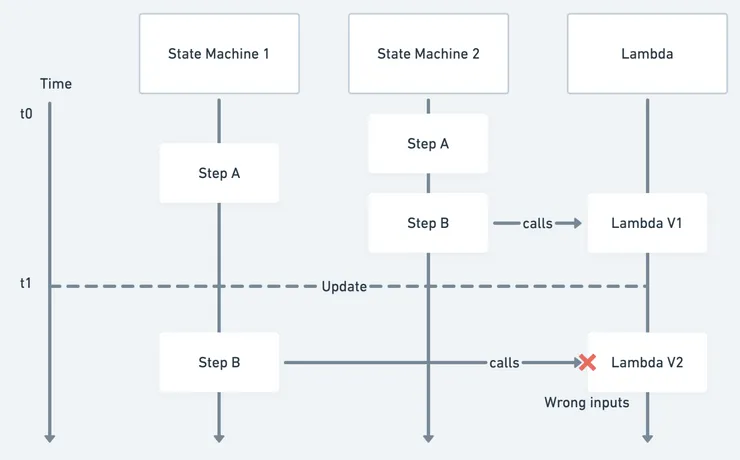
To answer these questions AWS gives us the very useful useExactVersion. By setting this parameter
to true in the configuration of a step we tell AWS to synchronise the version of the state machine with the lambda called
in the step. This way AWS keeps a version of lambda for each version of currently running state machines. To answer our
initial question : no, AWS will not call the new lambda for old state machines. So, as I said earlier, with this tool we
hadn’t really encountered big problems linked to versioning. But of course just like the stack had its limits so does useExactVersion.
###2. Secondary state-machines UseExactVersion works for lambdas called in a step. What happens when a step calls another state machine? In that case useExactVersion does not apply. Say we update state machine B which is called by state machine A. An old state machine A in version 1 will call a state machine B in the new version 2. If you have breaking changes between the versions, then you will have a problem.
For example, we wanted to sanitize the inputs of our whole process. To do so, we
need to change the inputs of all our steps. For the steps calling lambdas there was no problem thanks to useExactVersion
but the whole process still crashed because old sub state machines were expecting the complete input instead of the
sanitized version. The only way we could proceed was to duplicate the whole state machine like we did when we wanted to
split the stacks. This would lead to a third concurrent stack, which we judged too costly and lead us to abandon the
idea of sanitizing the inputs.
###3. Modifying the steps That is not the only problem we encountered with versioning. Adding a new step to an existing state machine is not a problem and modifying the execution of a step is also feasible. But what happens when you want to delete a step? We thought about it and concluded that if we kept the code for the lambda that was called, it wouldn’t be a problem. Indeed, already running state machines would still have the definition of the step and since the code for the called lambda still exists, everything would be fine. Of course it wasn’t.
To be able to execute certain tasks, to call lambdas for example, AWS uses roles. For a step to be able to call a specific lambda function it needs the associated role. What we did not anticipate was that when we removed the step from the configuration of the state machine, the role generated for that step was also removed. That means that when an old state machine tried to call the removed step it did not have the role necessary. We had two options:
- Replace the automatic generation of roles and manually add the needed roles in the configuration (over a hundred roles)
- Keep the step in the state machine and put it somewhere it would not be reached. Although the second option felt like hiding the mess under the rug, we were pressed for time, so we decided it was the more pragmatic solution.
##III. Conclusion With these specific examples to illustrate the difficulties of versioning with AWS Cloudformation and Step Functions, I want to more generally show you that state machines are made to be deployed rarely. If you want to deploy a new version it is best to deploy a whole new state machine rather than update the current one. Now that is quite a limiting aspect, since we often work with products that are already in production, and we continuously upgrade them. If you need to use a state machine like architecture and can’t afford to seldom deploy new versions I do have a recommendation. In a new project we have been using Camunda which allows you to code state machines on your Springboot (a Java framework) server. I found that it has many advantages over AWS. Mostly it has three functionalities I like :
- It is less complex than AWS (no roles for example) and has a gui to create the state machine
- It allows you to migrate state machines from one version to another if there are no breaking changes
- It has an integrated REST engine that allows you to easily manipulate the state machine (change the current step, stop/start state machines etc.)
With that said, I hope this article either helped you on your journey with AWS and State machines or better prepared you to better start using these technologies.


