As A Developer, I know how to talk to my PO about existing code
Alex de Boutray9 min read

Cover photo by You X Ventures on Unsplash
—
Monday, 10am. You’re around a table with a new team, looking at a product owner presenting the project you’ll be working on for the next few months.
While this project wouldn’t be the core software of your company, it would play an integral part in the firm’s development over the next few years. The PO wants it to be done quickly and cleanly so that you can all get back to improving the main product. To help achieve that goal, they’ve found an old prototype that had been in a drawer for a few months - or even better, an open source solution doing something similar.
This should be fairly easy then: take the existing software, add what we need, and deliver.
tl;dr
There are many different ways we can find value in existing code, like product inspiration or architecture ideas.
Lean principles should not be forgotten when dealing with old or open source code.
Communication may become more difficult. We offer a few tips and a milestone-based feature/cost analysis tool to ensure everyone is on the same page.
A few thoughts to start with
- Existing software has a lot of value outside of code itself. When approached carefully, it can provide valuable product insights and inspiration. It will prevent you from repeating mistakes, give you industry knowledge that you may not already possess… And even the code is useful, since you can let it inspire you architecturally, without the baggage of style of language specificities.
- Development resources and available skills can drastically impact your plans. For example, we once had a project based on existing Java code but no Java developer on the team. The decisions we made were obviously influenced by that fact and a different team with Java developers might have reached a different conclusion. Both could be equally valid! You should help your Product Owner by considering alternative options, for example, “bringing in a contractor with X experience could reduce development time by Y.”
- Defining concrete, near-future milestones helps us focus on the short term and make tough decisions, which is especially important in a startup environment.
- Existing code sets expectations and introduces bias in the way we think about the project. This clouds judgment and you may find the team struggling to communicate effectively and agree on the best way forward. This article will dig deeper into this issue and offer a few tools to help your team address it.
Human see, human want
Thanks to agile, everyone nowadays pays at least lip service to the notion that code only has value if it serves the user. It’s the reason we work with stories and try to keep our sprints short: the more user feedback we can incorporate in our process, the less worthless code we produce.
I’ve noticed that all this tends to be disregarded when trying to incorporate existing code. Both the devs and the PO like shiny new things.
The PO sees a cool feature in a demo and all of a sudden it’s a requirement in your project. You thought you were in for a simple time tracking app? Here come Face ID, SSO, custom transitions and a full-blown local database.
Devs easily adopt a black and white approach. “We’ll just incorporate the open source code, it’s free” and “the old code is just too bad, I have to redo it from scratch” are two sentences that I’ve said many many times, often based on my personal preferences for the technologies used. This can bias the opinion of the unsuspecting PO and deteriorate your relationship with them when your actual speed differs greatly from the planned one.
For example, if you’re looking at some oddly written code in a language you’re not familiar with, you might overestimate threefold the complexity of implementing it. Your PO, who’s used to you not overshooting my more than 50%, might interpret this as intentional and trust you less for it.
On the other end of the spectrum, if you promise something will be “free” (never a good move) and you end up spending a week on it, other features will be delayed and the whole project will suffer as a result.
So how can we align everyone’s expectations and settle on a common analysis of the situation?
Back to the drawing board
The next step is a very classic one: write user stories. Forget about the “free” existing code, just define your product as you would a new one. Depending on your company and team culture, this might be a task that only the PO works on but outside input - especially from user-facing stakeholders, or even better, users themselves - is always welcome.
The one question that should be on everyone’s mind during the prioritization phase should be “Do OUR users actually want this or are we just copying the other product?“. It may sound silly, but I’ve found double-checking this point saved us a lot of time. The other question to ask is “could we release WITHOUT this feature?” or “could the user benefit from the rest, even without this feature?“. This forces prioritization. I’ve seen features originally touted as critical continuously fall deeper down in the backlog, and eventually be dropped altogether just by asking this question.
The prioritization should also be carried a little more into the future than usual, because we’ll want to be able to assess the potential impact of using existing code in the medium term. If you usually work with weekly sprints and two weeks of backlog, you may miss out on benefits from the existing code by failing to foresee the need for some features or architectural choices.
For example, on one of our projects, extending our rough planning to two months allowed us to look into versioning and realize that the open source code we were adapting had a clever, working versioning system that we could just copy and paste if we designed our objects in a certain way. As a rule of thumb, staying close to the existing code will give you some options for the future, which have value.
Try to define some frequent milestones (maybe once a month, depending on the scope of your project) and define the specs of the product at that point. You may want to get a bit deeper than usual into their definitions and the technical strategies to achieve them. This will help us use the tools demonstrated later in this article.
In particular, you should have a decent idea of how your new code might interact with the existing one: are you going to rewrite an API? Use the existing one? Are you familiar with it? What would it take for you to be able to write this feature right now?
But wait, didn’t we have existing code?
Yes we did! Now is the time to get back to it.
An existing chunk of code will have two effects on your work to reach a milestone:
- It will help you complete some user stories at a lower cost. If the outside code does exactly what you want, you’ll only have to spend a little time fitting it into your code. If it does not, then this will cost you some tweaks but the overall cost should be lower than writing everything from scratch.
- It will also slow you down on everything else. Even if it’s only a little, the architecture or style compromises that you will have to make will have an adverse impact on your overall speed.
The secret is to be able to quantify the effects. It is evidently impossible, but you will have to get a good enough estimate to decide which strategy to choose. On larger projects where the potential to integrate a lot of existing code exists, it might be worth getting real life data by actually integrating a feature from existing code and analyzing your execution speed.
Another useful tool to plan work is the milestones we previously defined. They can help us analyze the impact of existing code on time and feature constraints (a.k.a. deliverables). Below is a graphical visualization that we used in one of our projects.

To reach milestone 1, we have to develop 3 features: bootstrapping the project, implementing a basic auth and the Facebook one. Since we already have the first two in the existing code (and we consider the integration cost to be zero for simplicity), they do not require additional time or money.
Under the y-axis are the features from the existing code not yet integrated into our product.
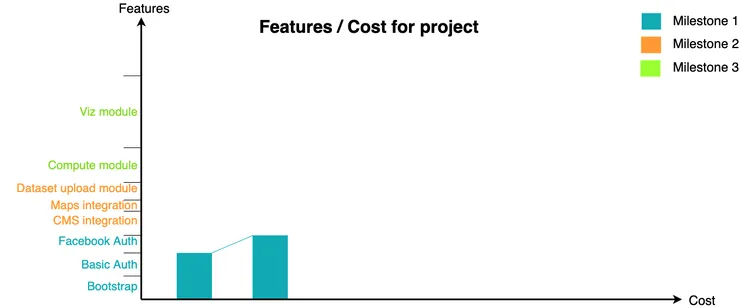
To complete milestone 1, we have to build the Facebook integration. To do this, we spend time and money with the first derivative of the curve being our development speed or development cost.
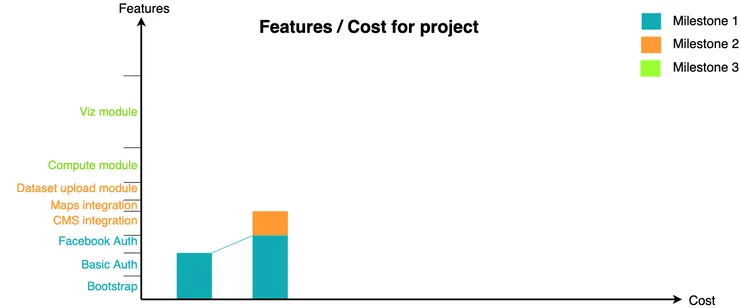
We then start milestone 2, for which we can take the CMS integration from the existing code.
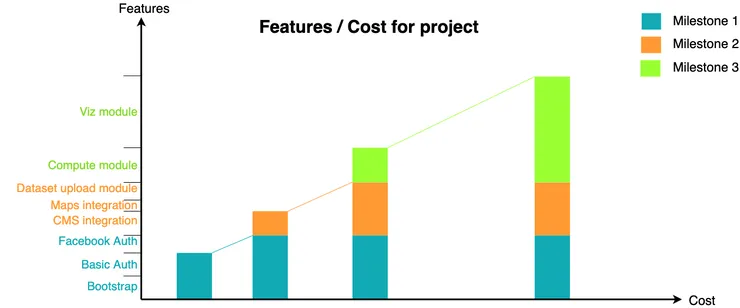
We repeat the process for all milestones and all features.
The constraints in this graph are the (x,y) coordinates of every milestone. They represent time / feature coupling that you have to respect for corporate and/or other reasons. They could be demos, client deployments, etc. In the end, they’re the only thing you need to account for.
What’s next?
We’ve only touched one of several aspects of working with existing code. I believe the most important thing in this situation is to keep a common language amongst the team that you can use to have productive discussions. In my experience, the most frustrating disagreements happen when one member of the team struggles to their ideas to the others. In these situations, we leverage the tools presented in this article to help us stay on track and be more productive.
Keep in mind that this is just an inspiration. Design your own tools! Your team’s needs will vary with the different personalities and skillsets involved, requiring bespoke solutions.


