Store your data in AWS Serverless architecture
Corentin Doue6 min read
Before building a serverless app, it is important to truly understand how serverless works in AWS and what modules are available and useful for such an architecture. This article is a follow-up to the previous article Understand AWS serverless architecture in 10 minutes.
It’s an overview of the storage services you could use to build your architecture:
- Relational Database Service (RDS)
- DynamoDB
- Simple Storage Service (S3)
- ElastiCache
- Systems Manager Parameter Store
RDS

Relational Database Service is the service to manage relational databases in AWS.
Relational databases are the most popular across the web community but they are not recommended in a serverless architecture:
- they are not on-demand provisioned which breaks the scalability of your serverless app.
- they are connection based: the common use case of RDS is a virtual machine which establishes a connection with the RDS and exchanges SQL requests. With a serverless architecture, each starting lambda needs to establish a connection that slows its cold start. Moreover, there will be a lot of concurrent connections to the RDS which will slow the requests. So the more users you will have, the slower your app will be.
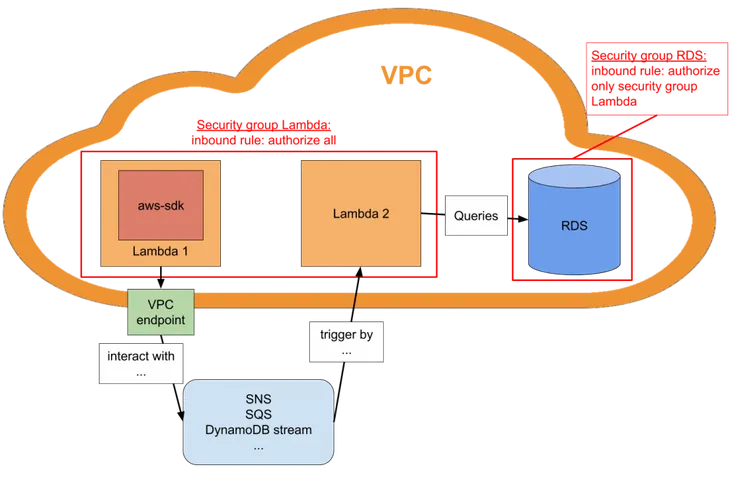
- they require you to use a Virtual Private Cloud to secure them: lambdas are by default not in a VPC. To communicate with your RDS, you need to put your lambdas in the same VPC (or make the RDS public which is not recommended). To do so, you need to set up a VPC with security groups. Moreover, you need to set up a VPC endpoint to be able to use from your lambda the AWS services that can’t be in VPC: SNS, SQS, DynamoDB, S3, … It adds complexity to your architecture.
Aurora Serverless (now available for MySQL and Postgres) offers an on-demand provisioned and priced alternative of common RDS.
It solves the first issue mentioned previously about RDS as it is designed for serverless. It also improves the second issue: the cold start of the connection is still here but the capacity of the database will grow with the charge of your app and be able to handle the concurrents connexions. The VPC issue remains a drawback.
DynamoDB

DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
It is the best way to store data in a serverless architecture. The provisioning and the pricing are on-demand which makes your DynamoDB scale with the rest of your application.
Moreover, the AWS-SDK for DynamoDb makes it easy to store and retrieve data from lambda and the stream is a good asset to build complex architectures by triggering other lambdas on table activities.
S3

S3 (Simple Storage Service) is a highly scalable, reliable, fast and inexpensive data storage infrastructure.
It is the best way to store files in a serverless architecture. The provisioning and the pricing are on-demand which makes S3 compatible with serverless.
Moreover, the AWS-SDK for S3 makes easy to retrieve, process and store files from a lambda. The notifications system is a good asset to build complex architecture by triggering other lambdas on bucket activities.
ElastiCache

ElastiCache is a service that makes it easy to set up, manage, and scale a distributed in-memory data store or cache environment. It supports two engines: Redis and Memcached.
In-memory key-value stores provide ultrafast access to data (submillisecond latency). Querying a database is always slower and more expensive than locating a key in a key-value pair cache.
The main drawback of using cache is the unreliability. You are not 100% sure to retrieve the data you stored. You should use it to provide quick access to data while having the same data persisted in a database as a backup.
There is one more drawback of using ElasticCache in serverless architecture: it must be in a VPC.
So there are the same problems as RDS: lambdas are by default not in a VPC. To communicate with your ElastiCache, you need to put your lambdas in the same VPC. By doing so, you need to set up a VPC endpoint to be able to use from your lambda the AWS services that can’t be in VPC: SNS, SQS, DynamoDB, S3, … It adds complexity to your architecture.
Systems Manager Parameter Store
Systems Manager Parameter Store provides secure storage for configuration data management and secrets management. It’s useful to share a few data between your lambdas such as environment variables.
Security
To build your architecture you also need to know how you will secure it. There are two ways of setting the authorizations of your services: IAM roles and VPC.
IAM Role

Unless you are using a service that specifically requires a VPC (RDS and ElastiCache), the simplest and recommended way is to give an IAM role to your lambdas which contain the right to interact with the other services. Do not give too many rights to your lambdas, try to create a role with only the rights needed to execute your lambdas.
VPC

If you need to use an RDS or an ElastiCache, you will need to set up a Virtual Private Cloud.
To allow your lambdas to communicate with your RDS or ElastiCache, you should put the lambdas in the same subnets (and therefore in the same VPC) as your RDS or ElastiCache. You should also create a security group dedicated to your lambda and then allow the security. group of your RDS or ElastiCache to accept connexions from the security group of your lambdas.
Moreover, you need to set up:
- a VPC endpoint to be able to use the AWS services that can’t be in a VPC (SNS, SQS, DynamoDB streams, …) from your lambda.
- a NAT GateWay to be able to access the internet from your lambda. It’s complicated to set up, you can find a complete guide here.
Conclusion
If you have also read Understand AWS serverless architecture in 10 minutes, you now have the basic knowledge to understand the architectures in serverless and start building your own.
I tried to expose, the most common AWS services which could be used in serverless architecture, but there are a lot more which could be used inside lambdas code through SDKs.
Serverless is new and the possibilities of structures evolve as quickly as AWS adds serverless features to its services. This article will probably need recurrent updates, feel free to suggest it in comments.