Scraping with Scrapy and Django Integration
Henriette Brand7 min read
If you already know what scraping is, you can directly jump to how I did it
What is scraping?
Scraping is the process of data mining. Also known as web data extraction, web harvesting, spying.. It is software that simulates human interaction with a web page to retrieve any wanted information (eg images, text, videos). This is done by a scraper.
This scraper involves making a GET request to a website and parsing the html response. The scraper then searches for the data required within the html and repeats the process until we have collected all the data we want.
It is useful for quickly accessing and analysing large amounts of data, which can be stored in a CSV file, or in a database depending on our needs!
There are many reasons to do web scraping such as lead generation and market analysis. However, when scraping websites, you must always be careful not to violate the terms and conditions of websites you are scraping, or to violate anyone’s privacy. This is why it is thought to be a little controversial but can save many hours of searching through sites, and logging the data manually. All of those hours saved mean a great deal of money saved.
There are many different libraries that can be used for web scraping, e.g. selenium, phantomjs. In Ruby you can also use the nokogiri gem to write your own ruby based scraper. Another popular library is is beautiful soup which is popular among python devs.
At Theodo, we needed to use a web scraping tool with the ability to follow links and as python developers the solution we opted for was using theDjango framework with an open source web scraping framework called Scrapy.
Scrapy and Django
Scrapy allows us to define data structures, write data extractors, and comes with built in CSS and xpath selectors that we can use to extract the data, the scrapy shell, and built in JSON, CSV, and XML output. There is also a built in FormRequest class which allows you to mock login and is easy to use out of the box.
Websites tend to have countermeasures to prevent excessive requests, so Scrapy randomises the time between each request by default which can help avoid getting banned from them. Scrapy can also be used for automated testing and monitoring.
Django has an integrated admin which makes it easy to access the db. That along with the ease of filtering and sorting data and import/export library to allow us to export data.
Scrapy also used to have a built in class called DjangoItem which is now an easy to use external library. The DjangoItem library provides us with a class of item that uses the field defined in a Django model just by specifying which model it is related to. The class also provides a method to create and populate the Django model instance with the item data from the pipeline. This library allows us to integrate Scrapy and Django easily and means we can also have access to all the data directly in the admin!
So what happens?
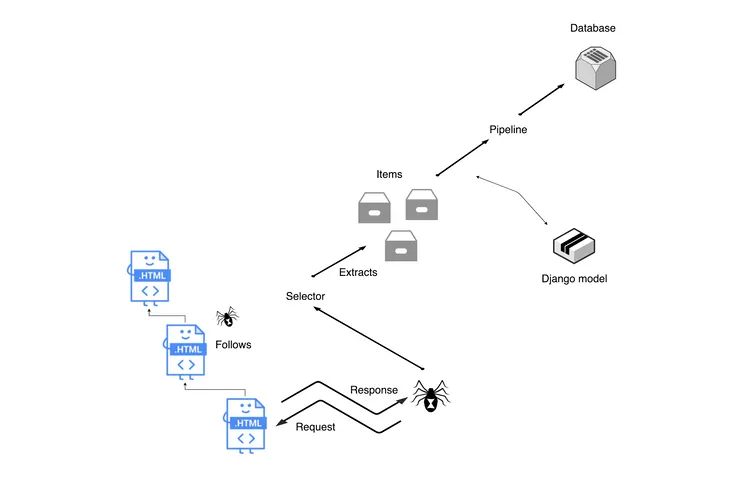
Spiders
Let’s start from the spider. Spiders are the core of the scraper. It makes the request to our defined URLs, parses the responses, and extracts information from them to be processed in the items.
Scrapy has a start_requests method which generates a request with the URL. When Scrapy fetches a website according to the request, it will parse the response to a callback method specified in the request object. The callback method can generate an item from the response data or generate another request.
What happens behind the scenes? Everytime we start a Scrapy task, we start a crawler to do it. The Spider defines how to perform the crawl (ie following links). The crawler has an engine to drive it’s flow. When a crawler starts, it will get the spider from its queue, which means the crawler can have more than one spider. The next spider will then be started by the crawler and scheduled to crawl the webpage by the engine. The engine middlewares drive the flow of the crawler. The middlewares are organised in chains to process requests and responses.
Selectors
Selectors can be use to parse a web page to generate an item. They select parts of the html document specified either by xpath or css expressions. Xpath selects nodes in XML docs (that can also be used in HTML docs) and CSS is a language for applying styles to HTML documents. CSS selectors use the HTML classes and id tag names to select the data within the tags. Scrapy in the background using the cssselect library transforms these CSS selectors into xpath selectors.
CSS vs Xpath
data = response.css("div.st-about-employee-pop-up")
data = response.xpath("//div[@class='team-popup-wrap st-about-employee-pop-up']")
Short but sweet: when dealing with classes, ids and tag names, use CSS selectors. If you have no class name and just know the content of the tag use xpath selectors. Either way chrome dev tools can help: copy selector for the element’s unique css selector or you can copy its xpath selector. This is to give a basis, may have to tweak it! Two more helper tools are XPath helper and this cheatsheet. Selectors are also chainable.
Items and Pipeline
Items produce the output. They are used to structure the data parsed by the spider. The Item Pipeline is where the data is processed once the items have been extracted from the spiders. Here we can run tasks such as validation and storing items in a database.
How I did it
Here’s an example of how we can integrate Scrapy and Django. (This tutorial uses scrapy version 1.5.1, djangoitem version 1.1.1, django 2.1.4)
Let’s scrape the data off the Theodo UK Team Page and integrate it into a Django Admin Panel:
-
Generate Django project with integrated admin + db
-
Create a django project, with admin and database
-
Create app and add to installed apps
-
Define the data structure, so the item, so our django model.
## models.py from django.db import model class TheodoTeam(models.Model): name = models.CharField(max_length=150) image = models.CharField(max_length=150) fun_fact = models.TextField(blank=True) class Meta: verbose_name = "theodo UK team" -
Install Scrapy
-
Run
scrapy startproject scraper -
Connect using DjangoItem
## items.py from scrapy_djangoitem import DjangoItem from theodo_team.models import TheodoTeam class TheodoTeamItem(DjangoItem): django_model = TheodoTeam -
The Spider - Spiders have a start_urls class which takes a list of URLs. The URLs will then be used by the start_requests method to create the initial requests for your spider. Then using the response and selectors, select the data required.
import scrapy from scraper.items import TheodoTeamItem class TheodoSpider(scrapy.Spider): name = "theodo" start_urls = ["https://www.theodo.co.uk/team"] # this is what start_urls does # def start_requests(self): # urls = ['https://www.theodo.co.uk/team',] # for url in urls: # yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): data = response.css("div.st-about-employee-pop-up") for line in data: item = TheodoTeamItem() item["name"] = line.css("div.h3 h3::text").extract_first() item["image"] = line.css("img.img-team-popup::attr(src)").extract_first() item["fun_fact"] = line.css("div.p-small p::text").extract().pop() yield item -
Pipeline - use it to save the items to the database
## pipelines.py class TheodoTeamPipeline(object): def process_item(self, item, spider): item.save() return item -
Activate the Item Pipeline component - where the integer value represents the order in which they run for multiple pipelines
```
## scraper/settings.py
ITEM_PIPELINES = {"scraper.pipelines.TheodoTeamPipeline": 300}
```
11. Create a Django command to run Scrapy crawl - This initialises django in the scraper and is needed to be able to access django in the spider.
```
## commands/crawl.py
from django.core.management.base import BaseCommand
from scraper.spiders import TheodoSpider
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
class Command(BaseCommand):
help = "Release the spiders"
def handle(self, *args, **options):
process = CrawlerProcess(get_project_settings())
process.crawl(TheodoSpider)
process.start()
```
12. Run manage.py crawl to save the items to the database
Project Structure:
scraper
management
commands
crawl.py
spiders
theodo_team_spider.py
apps.py
items.py
middlewares.py
pipelines.py
settings.py
theodo_team
admin
migrations
models
Challenges and problems encountered:
Selectors!! Selectors are not one size fits all. Different selectors are needed for every website and if there is constant layout changes, they require upkeep. It can also be difficult to find all the data required without manipulating it. This occurs when tags may not have a class name or if data is not consistently stored in the same tag.
An example of how complicated selectors can get:
segments = response.css("tr td[rowspan]")
rowspan = int(segment.css("::attr(rowspan)").extract_first())
all_td_after_segment = segment.xpath("./../following-sibling::tr[position()<={}]/td".format(rowspan- 1))
line = all_td_after_segment.extract_first()
data = line.xpath("./descendant-or-self::a/text()")
more_data = line.xpath("substring-after(substring-before(./strong/text()[preceding-sibling::a], '%'), '\xa0')").extract_first()
As you can see, setting up the scraper is not the hard part! I think integrating Scrapy and Django is a desirable, efficient and speedy solution to be able to store data from a website into a database.