How to recode Big Brother in 15 min on your couch
Oussamah Jaber10 min read

How to recode Big Brother in 15 min on your couch
Face Recognition Explained
In this article, we will step by step implement a smart surveillance system, able to recognise people in a video stream and tell you who they are.
More seriously, we’ll see how we can recognise in real-time known faces that appear in front of a camera, by having a database of portraits containing those faces.
First, we’ll start by identifying the different essential features that we’ll need to implement. To do that, we’ll analyse the way we would to that, as human beings (to all the robots that are reading those words, I hope I don’t hurt your feelings too much and I truly apologize for the methodology of this article).
Ask yourself : if someone passes just in front of you, how would you recognise him ?
- You’ll need first to see the person
- You then need to focus on the face itself
- Then there are actually two possibilities.
- Either I know this individual and I can recognise him by comparing his face with every face I know.
- Or I don’t know him
Let’s see now how to the algo will do those different steps.
First step of the process : seeing the person
This is quite a simple step. We’ll simply need a computer and a webcam, to capture the video stream.
We’ll use openCV Python. With a few lines of code, we’ll be able to capture the video stream, and dispose of the frame one by one.
import cv2
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
frame = video_capture.read()
# Display the resulting frame
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
How to detect a face in a picture ?
To be able to find a face in the picture, let’s ask ourselves, what is a face and how can we discriminate a face from Gmail’s logo for example ?

We actually do it all the time without even thinking about it. But how can we know that easily that all these pictures are faces ?

When we look at those different pictures, photographs and drawings, we see that a face is actually made of certain common elements :
- A nose
- Two eyes
- A mouth
- Ears
- …
But not only are the presence of these elements essential, but their positions is also paramount.
Indeed, in the two pictures here, you’ll find all the elements that you’ll find in a face. Except one is a face, and one is not.

So, now that we’ve seen that a face is characterised by certain criterias, we’ll turn them into simple yes-no questions, which will be very useful to find a face in a square image.
As a matter of fact, the question “Is there a face in a picture ?” is very complex. However, we’ll be able to approximate it quite well by asking one after the other a series of simple question : “is there a nose ?” ; “Is there an eye ? If yes, is their two eyes ?” ; “Are there ears ?” ; “Is there some form of symmetry ?”.
All these questions are both far more simple than the complex question “Is there a face in the picture ?”, while providing us with information to know if part of the image is or is not a face.
For each one of these questions, a no answer is very strong and will tell us that there is definitely no face in the picture.
On the contrary, a yes answer will not allow us to be sure that there is a human face, but it will slightly increase the probability of the presence of a face. If the image is not a face, but it is tree, the answer to the first question “is there a nose ?” will certainly be negative. No need then to ask if there are eyes, or if there is some form of symmetry.
However, if indeed there is a nose, we can go forward and ask “are there ears?“. If the answer is still yes, this won’t mean that there is a face, but will slightly increase the likeliness of this possibility, and we will keep digging until being sufficiently confident to say that there is a face indeed.
The interest is that the simplicity of the questions will reduce drastically the cost of face detection, and allow to do real-time face detection on a video stream.
This is the principle of a detection method called “the cascade of weak classifier”. Every classifier is very weak considering that it gives only a very little degree of certitude. But if we do the checks one by one, and a region of the picture has them all, we’ll be at the end almost sure that a face is present here.
That’s why it is called a cascade classifier, because like a series of waterfalls, the algorithm will simply do a very simple and quick check, one by one, and will only move forward with another check if the first one is positive.
To do face detection on the whole picture, and considering that we don’t know in advance the size of the face, we’ll simply apply the cascade algorithm on a moving window for every frame.

What we’ve explained here is the principle of the algorithm. Lots of research has been made about how to use cascade for object detection. OpenCV has a built-in way to do face detection with a cascade classifier, by using a set of 6,000 weak classifiers especially developed to do face detection.
import cv2
opencv_path = 'm33/lib/python3.7/site-packages/cv2/data/'
face_cascade = cv2.CascadeClassifier(opencv_path + 'haarcascade_frontalface_default.xml')
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5)
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
Now that we can detect the face, we need to recognise it among other known faces. Here is what we got : 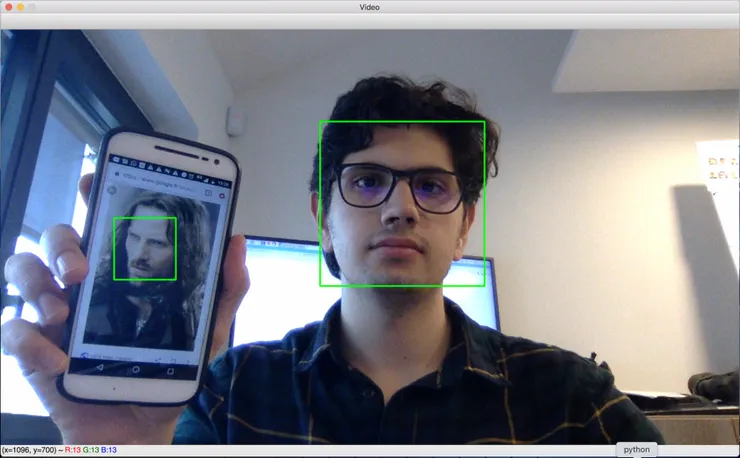
Face recognition
Now that we have a system able to detect a face, we need to make sense out of it and recognise the face.
By applying the same methodology as before, we’ll find the criterias to recognise a face among others.
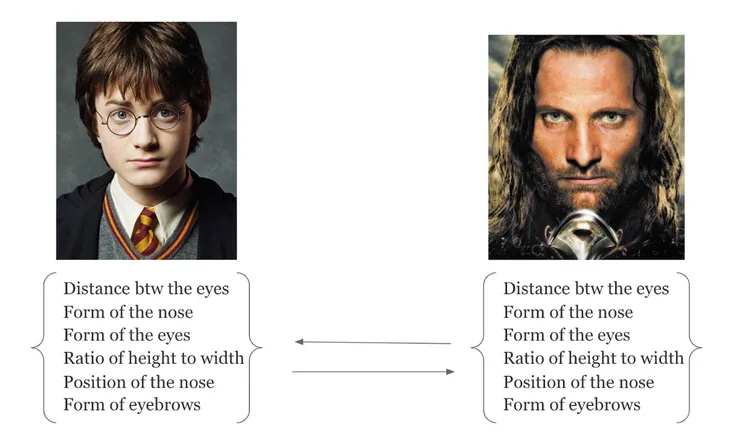
To do that, let’s look at how we differentiate between two faces : Harry Potter on one side, and Aragorn on the second.

Let’s make a list of the things that can differentiate them :
- Form of their nose
- Form of their eyes
- Their hair
- Color of their eyes
- Distance between the eyes
- Skin color
- Beard
- Height of the face
- Width of the face
- Ratio of height to width
Of course, this list is not exhaustive. However, are all those criterias good for face recognition ?
Skin color is a bad one for example. We’ve all seen Harry Potter or Aragorn after hard battles covered with dirt or mud, and we’re still able to recognise them easily.
Same goes for height and width of the face. Indeed, these measures change a lot with the distance of the person to the camera. Despite that we can easily recognise the faces even when their size changes.
So we can keep some good criterias that will really help recognise a face :
- Form of their nose
- Form of their eyes
- Distance between the eyes
- Ratio of height to width
- Position of the nose relative to the whole face
- Form of eyebrows
- …
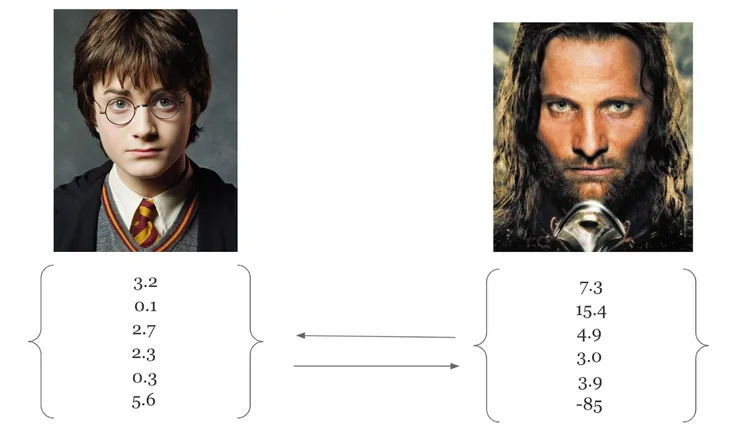
Let’s now measure all these elements. By doing this, we’ll have a set of values that describe the face of an individual. These measures are a discrete description of what the face looks like.
Actually, what we have done, is that we reduced the face to a limited number of “features” that will give us valuable and comparable information of the given face.
Mathematically speaking, we have simply created a vector space projection, that allowed us to reduce the number of dimensions in our problem. From a million-dimensions vector space problems (if the picture is 1MPixel RGB image, the vector space is of 1M * 3 dimensions) to a an approximately a-hundred-dimension vector space. The problem becomes far more simple !
No need to consider all the pixels in the picture at all, we only need to extract from the image a limited set of features. These extracted features can be considered as vectors that we can then compare the way we do it with any vector by computing euclidean distances for example.
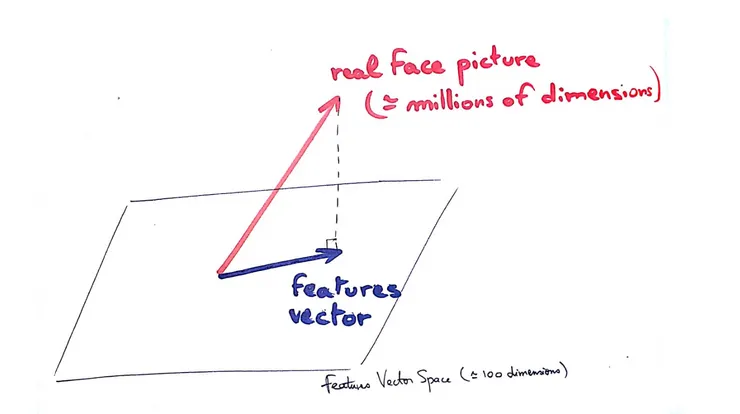
And just like that, comparing faces becomes mathematically as simple as computing the distance between two points on a grid, with only a few more dimensions ! To be simple, it’s as though, every portrait can then be described as a point in space. The closer points are, the more likely they describe the same face ! And that’s all !
When we find a face in a frame, we find its position in the feature-space and we look for the nearer known point. If the distance between the two is close, we’ll consider that they’re both linked to the same face. Otherwise, if the point representing the new face is too far from all the faces known, it means we don’t know this face.
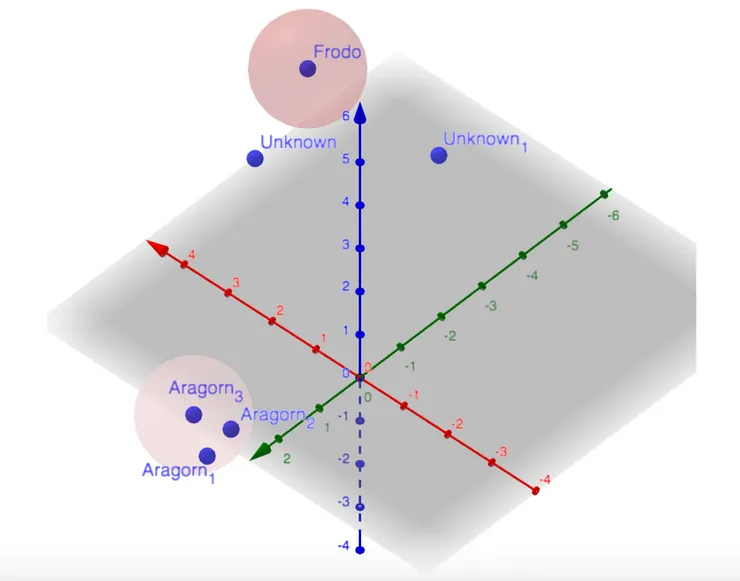
To implement that, we’ll use the face_recognition Python library that allows us to use a deep learning algorithm that extracts from a face a 128-dimension vector of features.
We’ll do it in two steps.
We first turn our portrait database into a set of computed feature-vectors (reference points like the Frodo point in the example above).
import face_recognition
import os
import pandas as pd
def load_image_file(file):
im = PIL.Image.open(file)
im = im.convert('RGB')
return np.array(im)
face_features = []
names = []
for counter, name in enumerate(os.listdir('photos/')):
if '.jpg' not in name:
continue
image = load_image_file(pictures_dir + name)
try:
face_features.append(face_recognition.face_encodings(image)[0])
names.append(name.replace('.jpg', ''))
except IndexError:
// happens when no face is detected
Continue
features_df = pd.DataFrame(face_features, names)
features_df.to_csv('database.csv')
Then, we load the database and launch the real-time face recognition:
import cv2
import pandas as pd
from helpers import load_database
import PIL
import numpy as np
import face_recognition
def load_image_file(file):
im = PIL.Image.open(file)
im = im.convert('RGB')
return np.array(im)
face_features = []
names = []
for counter, name in enumerate(os.listdir('photos/')):
if '.jpg' not in name:
continue
image = load_image_file(pictures_dir + name)
try:
face_features.append(face_recognition.face_encodings(image)[0])
names.append(name.replace('.jpg', ''))
except IndexError:
# happens when no face is detected
Continue
face_cascade= cv2.CascadeClassifier('m33/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml')
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5)
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
pil_im = PIL.Image.fromarray(frame[y:y+h, x:x+w])
face = np.array(pil_im.convert('RGB'))
try:
face_descriptor = face_recognition.face_encodings(face)[0]
except Exception:
continue
distances = np.linalg.norm(face_descriptors - face_descriptor, axis=1)
if(np.min(distances) < 0.7): found_name = names[np.argmin(distances)] print(found_name) print(found_name) #y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, found_name, (y, y-15), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
And here it comes !
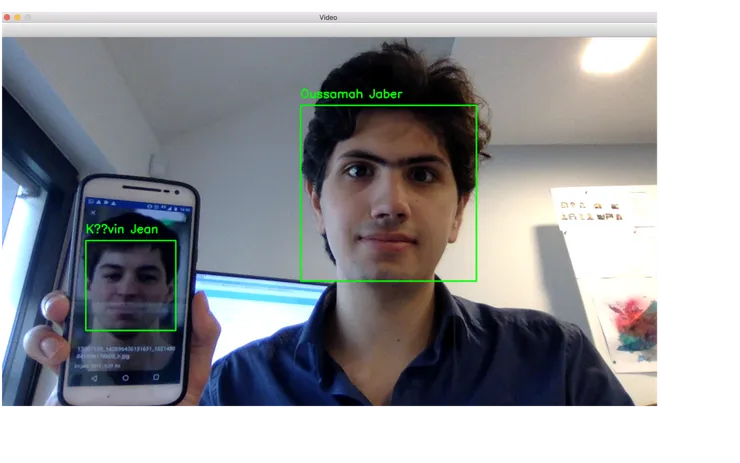
Here is a github repo with the code working : “https://github.com/oussj/big_brother_for_dummies”
External links I used :


{kind=link}